Questo articolo è una traduzione assistita dall’AI dell’originale in inglese, revisionata dall’autore.
TL;DR: l’attivazione zero-copy non riguarda solo l’evitare la duplicazione dei dati. Riguarda il cambiamento sul dove vive la verità sul cliente, dove vengono calcolate le decisioni, come le piattaforme di engagement si rapportano al warehouse e, sempre più, su cosa i sistemi di marketing agentico possono effettivamente ragionare. Il vero test non è se un vendor dice “zero copy”, ma se il copiare diventa una scelta architetturale intenzionale invece che l’impostazione di default.
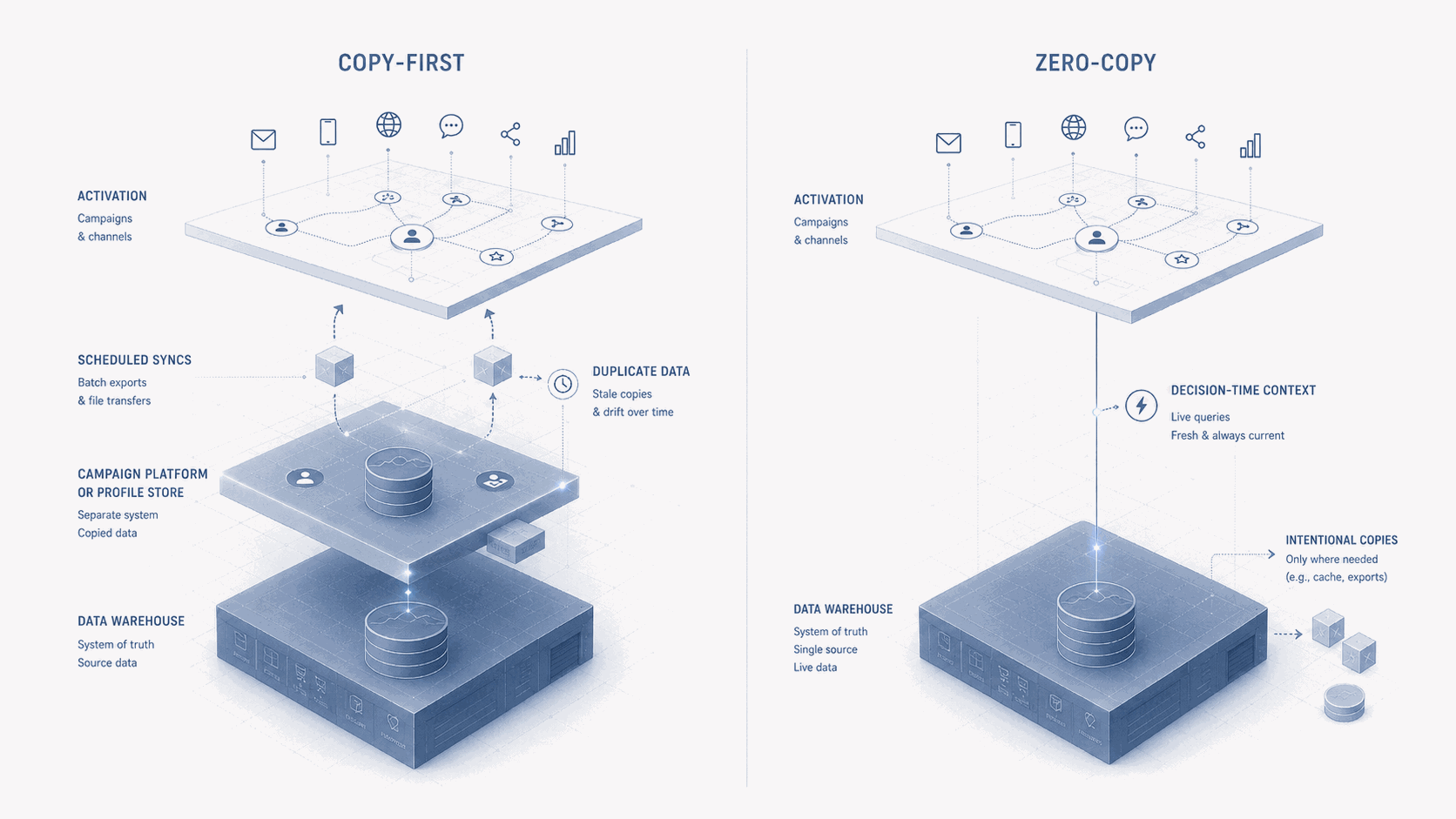
Per anni l’architettura del customer engagement si è retta su un assunto silenzioso: prima che una piattaforma possa agire sui dati del cliente, deve prima copiare quei dati al suo interno. Ogni copia è stata introdotta per un motivo, performance, autonomia del marketer, esecuzione sui canali, lock-in del vendor, ma ogni copia ha anche creato un altro punto in cui la verità sul cliente poteva divergere.
Consenso ormai obsoleto in un sistema, regole di soppressione assenti in un altro, affinità di prodotto ricalcolata nel warehouse mentre la piattaforma di campagna usava ancora il valore di ieri.
Quell’assunto sta iniziando a incrinarsi, e la direzione del cambiamento è visibile: le piattaforme di customer engagement cercano sempre più di attivare i dati dove già risiedono.
Cosa significa davvero zero copy
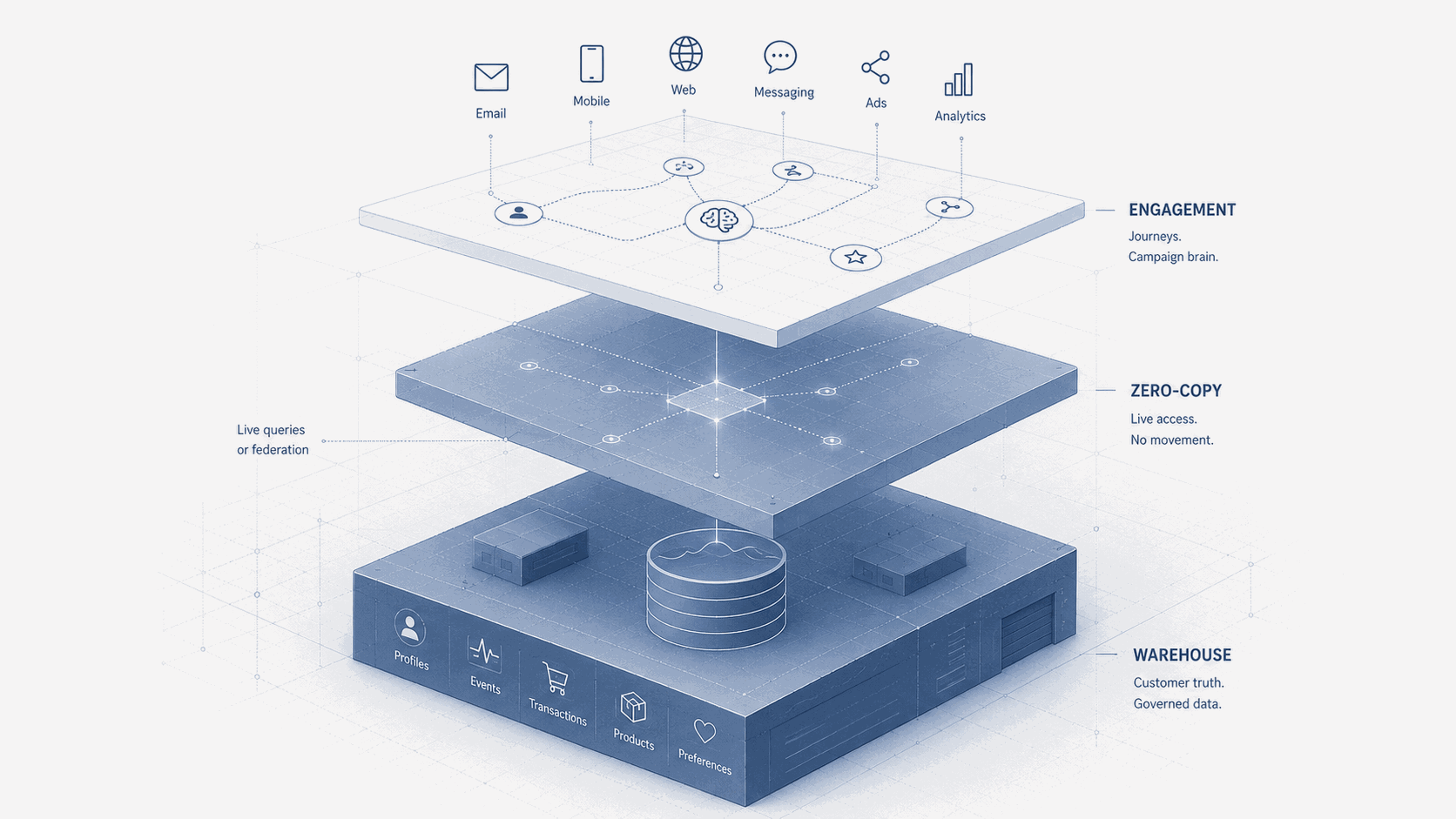
L’espressione “zero copy” è facile da vendere. Non significa sempre che nessun dato si muove mai, che nessun risultato di query viene mai messo in cache, che nessun contesto viene mai materializzato e che nessun log di attivazione viene mai memorizzato altrove. In un’architettura enterprise qualcosa si muove sempre ad un certo punto: una query viene eseguita, un risultato viene restituito, l’appartenenza a un’audience può essere materializzata, un evento di trigger può essere passato dentro un journey e un’interazione con un messaggio viene memorizzata per reporting, compliance, debugging o attribution.
Quindi la definizione utile non è teologica. Zero copy significa che la piattaforma di attivazione non ha bisogno di persistere un duplicato completo del dataset cliente sottostante prima di poter agire su di esso. Il warehouse, il lakehouse o la cloud data platform restano il substrato dati primario, e la piattaforma di engagement interroga, referenzia o riceve contesto selezionato da quel substrato quando ha bisogno di personalizzare, attivare un trigger, segmentare o decidere.
È uno spostamento architetturale significativo, perché il vecchio modello diceva: sposta i dati nella piattaforma, poi lascia che sia la piattaforma a decidere. Il nuovo modello dice sempre più: tieni i dati dove sono governati, e lascia che la piattaforma agisca su di essi da lì. Non è la stessa architettura.
Perché sta succedendo adesso
Lo zero copy non sta emergendo perché i vendor hanno improvvisamente scoperto che la duplicazione dei dati è poco elegante. Sta emergendo perché diverse pressioni stanno convergendo nello stesso momento.
La prima è l’ascesa del cloud data warehouse come vero sistema di verità aziendale. In molte organizzazioni Snowflake, Databricks, BigQuery o Redshift contengono già la visione più completa del cliente: transazioni, utilizzo del prodotto, fatturazione, loyalty, consenso, storico del service, comportamento digitale, eventi offline, score predittivi e attributi operativi.
La seconda è la delusione verso alcune implementazioni di CDP tradizionali. Molti CDP promettevano di diventare il database cliente centrale, ma nella pratica spesso sono diventati un altro database cliente, accanto al warehouse, parzialmente sincronizzato e spesso anche costoso da mantenere.
La terza è la crescita dei pattern di CDP composable. Strumenti come Hightouch e Census, insieme ai layer di attivazione warehouse-native, hanno riformulato la conversazione sul CDP attorno a un’idea semplice: se il warehouse contiene già il modello cliente fidato, perché ricostruire quel modello da un’altra parte prima di attivarlo?
La quarta è la pressione operativa sulle piattaforme di customer engagement. Le CEP devono supportare personalizzazione più ricca, triggering più rapido e decisioning più complesso senza chiedere a ogni cliente di duplicare in anticipo ogni possibile attributo nel profilo della piattaforma.
La quinta è l’AI. I sistemi di marketing agentico hanno bisogno di accesso al contesto cliente. Se il layer agentico riesce a vedere solo il profilo parziale memorizzato dentro la piattaforma di engagement, ragionerà a partire da una realtà parziale. Se può interrogare in sicurezza dati governati del warehouse, la qualità delle sue decisioni può migliorare, a patto che il modello di governance sia abbastanza solido.
Ecco perché lo zero copy non è solo un tema di integrazione dati. Sta diventando parte del modello operativo del customer engagement.
Il panorama dei vendor
Il mercato si muove nella stessa direzione generale, ma non tutti i vendor fanno la stessa cosa, e questa distinzione conta. Alcuni vendor sono warehouse-native per design. Alcuni stanno aggiungendo accesso zero-copy a piattaforme di engagement esistenti. Alcuni stanno migliorando l’ingestion dal warehouse, cosa utile ma comunque diversa dallo zero copy. Alcuni usano il termine in modo vago.
Per questo evito di trattare lo zero copy come una funzionalità binaria. La domanda migliore è: che ruolo gioca il warehouse nell’architettura? Una piattaforma che importa da Snowflake su uno schedule e una piattaforma che interroga Snowflake al momento della decisione possono sembrare quasi identiche in una demo e comportarsi in modo molto diverso in produzione. Teniamo a mente la distinzione tra import e federazione lungo tutta la sezione che segue, perché è la linea che davvero separa le categorie.
Hightouch e il punto di partenza warehouse-native
Hightouch è l’espressione più pulita del pattern di CDP composable. La sua premessa architetturale è che il warehouse è la fonte di verità e che il layer di attivazione dovrebbe operare attorno ad esso invece di sostituirlo. Logica di audience, lavoro sull’identità, decisioning e attivazione sono costruiti sopra i dati del warehouse, con gli strumenti a valle che ricevono gli output di cui hanno bisogno.
È diverso dal classico modello di CDP a pacchetto. Nel modello classico il CDP vuole fare ingestion dei dati cliente, unificarli, memorizzarli, segmentarli e attivarli. Nel modello composable il warehouse resta il principale ambiente dati cliente, mentre il layer simile a un CDP fornisce accesso al marketer, capacità di identità, costruzione di audience, reverse ETL, attivazione e, sempre più, decisioning guidato dall’AI. Quella differenza non è cosmetica: cambia il modello di ownership dei dati.
Salesforce Data 360 e Adobe: zero copy su scala di suite
Salesforce e Adobe vanno letti insieme, perché entrambi affrontano lo zero copy non dal solo lato CDP, ma dal lato di una grande suite di experience integrata.
Salesforce ha reso la connettività zero-copy una parte centrale della storia di Data 360. Il meccanismo è l’Advanced Query Pushdown: invece di creare repliche complete nel data lake di Data 360, delega il recupero al warehouse di origine attraverso una query di pushdown ottimizzata che restituisce solo i dati necessari. Supporta due metodi di federazione, query federation su JDBC (Snowflake, Databricks, BigQuery, Redshift) e file federation su standard aperti come Apache Iceberg e Parquet, ed è bidirezionale: Salesforce può condividere insight verso quelle piattaforme senza copiare i dati. La promessa più ampia è connettere i dati aziendali a CRM, marketing, service, analytics e workflow agentici senza ricostruire di continuo le pipeline. È potente, soprattutto nelle organizzazioni Salesforce-centriche. In base al materiale pubblico, però, Salesforce si colloca più vicino all’estremo della federazione-con-materializzazione che a quello della query puramente live: l’architettura è zero-copy nella direzione ma dipende ancora da step di armonizzazione strutturati prima che i dati diventino pienamente attivabili nell’esecuzione marketing. Le domande di valutazione che contano di più sono: dove viene messo in cache il contesto, quali oggetti devono essere materializzati dentro strutture controllate da Salesforce e qual è la latenza reale dall’aggiornamento del warehouse alla decisione di campagna.
Adobe porta la stessa idea nel mondo di Experience Platform attraverso la Federated Audience Composition. La proposta è esplicita sul pattern: un modello di query zero-copy che permette ai team di costruire e arricchire audience direttamente sui dataset in Snowflake, Databricks o Redshift senza copiare i dati sottostanti, così il warehouse resta il system of record e la piattaforma evita il profile bloat. L’audience risultante è comunque pienamente attivabile dentro Real-Time CDP e nei canali Adobe a valle. Per le realtà certificate Adobe è uno spostamento significativo, perché lascia che Real-Time CDP si comporti come motore di engagement sopra una fondazione composable invece di insistere che ogni attributo venga prima fatto entrare nel profile store. Vale la stessa cautela di Salesforce: la solidità della federazione dipende dalla connettività (supporto al private link, governance, latenza) e dall’essere onesti su quali casi d’uso richiedono ancora attributi di profilo materializzati.
Braze e lo zero-copy engagement
Braze è interessante perché non è un vendor di CDP composable per origine. È una piattaforma di customer engagement, con forte orchestrazione cross-channel, mobile engagement, personalizzazione event-driven ed esecuzione di campagne. Quindi quando Braze aggiunge capacità zero-copy, il segnale è diverso.
Braze già supportava Cloud Data Ingestion e CDI Segments, dando ai team modi per usare i dati del warehouse nei workflow di Braze. La release del 30 aprile 2026 ha spinto questo più a fondo nell’esecuzione dei journey con i trigger zero-copy CDI Canvas: i marketer possono attivare le Canvas da dati del warehouse o di S3 e passare campi di contesto dentro la Canvas come proprietà di personalizzazione senza persistere quei campi sui profili utente di Braze. Braze non memorizza un backup dei risultati della query, e le proprietà di contesto possono essere conservate nei sistemi interni fino a trenta giorni per finalità operative, cosa che vale la pena notare nelle review di governance ma è una cosa diversa dal ricostruire il profilo.
Questo non trasforma Braze in un CDP warehouse-native. Fa qualcosa di più interessante: riconosce che una CEP non ha bisogno di possedere tutti i dati cliente per essere operativamente potente.
Insider One e la segmentazione zero copy
Insider si è mossa con decisione in questa direzione, e il segnale più chiaro è recente. Allo Snowflake Summit del 2 giugno 2026, Insider One ha lanciato Zero Copy Segmentation for Snowflake, che si basa sulla precedente partnership di Secure Data Sharing del 2025 ma va oltre, dentro il pattern di attivazione stesso. Il meccanismo è la parte interessante: invece di fare ingestion dei dati cliente grezzi, Insider esegue le query di segmentazione direttamente su Snowflake e memorizza solo l’appartenenza all’audience risultante per l’attivazione. Le audience possono essere aggiornate al momento dell’invio rispetto ai dati più recenti disponibili, e l’intero flusso opera dentro il modello di sicurezza e permessi esistente di Snowflake.
È vicina all’espressione lato CEP più pulita dell’idea di cui parla questo articolo. La piattaforma tiene i dati grezzi governati dove risiedono, persiste solo ciò che le serve per agire (l’appartenenza, non il dataset) e porta la freschezza in avanti al momento dell’invio invece che al momento dell’export. Insider inquadra i casi a maggior valore come targeting comportamentale in tempo reale, segmentazione guidata da AI e da modelli come le audience di propensity o risk-based, e attivazione sensibile alla compliance dove i dati devono restare dentro ambienti governati, che è esattamente dove il modello import-poi-attiva tende a rompersi. Nel retail, nei servizi finanziari e nel travel, dove i dati sono grandi, volatili, sensibili e time-critical, quella combinazione conta. La domanda rilevante non è mai stata semplicemente se esista un’integrazione con Snowflake, perché molte piattaforme possono importare da Snowflake. È se la piattaforma possa usare i dati del warehouse come substrato operativo live, e su questa evidenza Insider si colloca saldamente all’estremo della federazione dello spettro. Serve cautela in quanto si tratta di un lancio recentissimo, annunciato a un summit di vendor: il pattern è solido, ma una valutazione reale merita lo stesso scrutinio di ogni altra affermazione di questo articolo.
Segment, Treasure AI e il riposizionamento del CDP
Twilio Segment si sta muovendo verso casi d’uso di audience più warehouse-native. Advanced Audiences e Linked Audiences puntano in questa direzione permettendo ai marketer di costruire audience a partire da dati di entità connessi al warehouse e da condizioni aggregate, senza chiedere agli ingegneri di precalcolare ogni metrica in anticipo. Sotto sta il Data Graph, un layer semantico che definisce le relazioni tra il profilo Segment e le entità del warehouse come account, abbonamenti, nuclei familiari e prodotti, con i risultati riscritti verso Snowflake, Databricks, BigQuery o Redshift.
Treasure Data, ora Treasure AI, è un altro segnale utile, perché inquadra esplicitamente le capacità di CDP composable attorno al costruire sopra l’infrastruttura warehouse esistente, incluse connessioni zero-copy live con Snowflake. La storia di categoria sta diventando visibile: i CDP non competono più solo per essere il luogo dove i dati cliente vengono memorizzati. Competono per essere il luogo dove i dati cliente diventano utilizzabili. È un lavoro diverso.
Bloomreach e Iterable: la differenza tra import e zero copy
Bloomreach e Iterable vanno trattati insieme, perché entrambi illustrano quanto la distinzione tra import e zero-copy conti nella pratica.
L’integrazione Snowflake di Bloomreach rende più facile portare profili cliente, eventi e dati di prodotto da Snowflake dentro Bloomreach Engagement. Per molte organizzazioni è davvero utile: può ridurre il lavoro di engineering e migliorare la freschezza delle campagne. Ma in base al materiale pubblico che ho esaminato, la storia Snowflake è inquadrata principalmente come import nativo dentro Bloomreach Engagement, non come modello operativo zero-copy-first.
Iterable rientra nella stessa categoria. La sua capacità warehouse nativa, Smart Ingest, importa dati da Snowflake dentro Iterable, e un’integrazione separata gestisce l’export in uscita. La precedente partnership di Snowflake Secure Data Sharing ha aggiunto sopra la condivisione governata dei dati, ma il baricentro resta l’import warehouse-connected, non la federazione live al momento della decisione.
Nessuna delle due collocazioni è una critica. Warehouse-connected non è la stessa cosa di warehouse-native, e l’automazione dell’import non è la stessa cosa dell’attivazione zero-copy. Nelle valutazioni reali la distinzione conta proprio perché entrambi i pattern possono sembrare simili in una demo e comportarsi in modo diverso in produzione.
Perché lo zero copy conta
Il beneficio più ovvio è la duplicazione ridotta, e con essa meno punti in cui la verità sul cliente può divergere, il problema con cui questo articolo si è aperto. È reale, ma non è tutta la storia. I benefici più importanti sono architetturali, e tornano tutti a una singola idea: il copiare diventa una decisione deliberata invece che un riflesso.
1. Le decisioni possono essere più fresche
Una decisione in un journey vale solo quanto i dati disponibili nel momento in cui la decisione viene presa. Sembra ovvio, eppure molte architetture di marketing girano ancora su export schedulati, sincronizzazioni batch e attributi di profilo aggiornati a intervalli fissi. Per alcuni casi d’uso va bene. Per altri no. Un cliente che ha appena acquistato non dovrebbe ricevere un messaggio di carrello abbandonato perché l’attributo di soppressione non si è ancora sincronizzato. Un cliente che ha aperto un caso di service ad alta priorità non dovrebbe ricevere un upsell aggressivo perché la piattaforma di marketing non lo sa ancora. Un cliente il cui consenso è cambiato non dovrebbe restare eleggibile perché lo strumento di engagement lavora da una copia obsoleta. I pattern zero-copy non rendono automaticamente tutto in tempo reale, ma spingono l’architettura più vicina al contesto del momento-decisione invece che al contesto del momento-preparazione-campagna.
2. L’AI ha bisogno di un substrato dati migliore
È la parte su cui continuo a tornare. Il marketing agentico sta arrivando più in fretta di quanto la maggior parte delle organizzazioni riesca a governarlo. Le piattaforme stanno aggiungendo agenti che generano audience, propongono journey, scrivono contenuti, spiegano le performance e, sempre più, agiscono per conto del marketer. Ma un agente può ragionare solo a partire da ciò che vede. Se vede solo il profilo interno dentro la CEP, allora quel profilo diventa la realtà dell’agente, e se il profilo è incompleto, obsoleto o scollegato dal modello cliente aziendale, l’agente opererà con falsa sicurezza.
Lo zero copy dà al layer agentico accesso a un substrato più ampio, più governato, più aggiornato, ma solo quando l’accesso è controllato, la lineage è comprensibile, i permessi sono ben progettati e le azioni dell’agente sono auditabili. Senza quelle condizioni, lo zero copy dà semplicemente all’agente una superficie più grande su cui sbagliare.
3. La valutazione delle piattaforme diventa più architetturale
Per anni le valutazioni delle CEP si sono concentrate pesantemente su funzionalità visibili: usabilità del journey builder, canali, template, UI di segmentazione, sperimentazione, reporting, generazione di contenuti con AI. Quelle cose contano ancora.
Ma lo zero copy introduce un set più profondo di domande che appartengono alla selezione della piattaforma, non a una fase di implementazione tardiva. Oggi mi chiederei:
- Dove avviene l’identity resolution, e dove vive il consenso?
- Dove vengono calcolate le definizioni di audience?
- Quali attributi devono essere persistiti nella piattaforma, e quali possono essere interrogati al momento della decisione?
- Qual è la latenza tra un aggiornamento del warehouse e un’azione di campagna?
- Cosa viene messo in cache, dove e per quanto tempo?
- Chi può creare un’audience da dati del warehouse, chi la approva e cosa mostra l’audit trail?
Questi non sono più dettagli implementativi secondari. Sono criteri di selezione.
Il legame con il CDP composable
Zero copy e CDP composable non sono la stessa cosa, ma appartengono allo stesso movimento architetturale. L’argomento del CDP composable non è mai stato solo risparmiare sulle licenze del CDP. Nella sua versione migliore, era evitare un secondo database cliente non necessario quando l’organizzazione aveva già investito pesantemente in una cloud data platform. La logica era semplice: se il warehouse contiene già i migliori dati cliente, perché estrarli, rimodellarli e ricostruirli dentro un CDP a pacchetto prima che i marketer possano usarli?
Quella domanda è diventata solo più rilevante, e ciò che è cambiato è che l’argomento non è più limitato ai vendor di CDP composable. Le CEP si stanno adattando, le suite si stanno adattando, i CDP si stanno riposizionando attorno ad esso, e i data warehouse e i lakehouse stanno diventando più operativi. Il mercato non sta dicendo che ogni azienda dovrebbe sostituire il proprio CDP con un layer di attivazione warehouse-native, cosa che sarebbe troppo semplicistica. Sta dicendo qualcosa di più sfumato: il warehouse sta diventando difficile da ignorare come baricentro dei dati cliente.
Questo non significa che il warehouse debba fare tutto. Non credo che il data warehouse debba diventare il journey builder, il motore email, il layer di messaggistica mobile o l’interfaccia del marketer per ogni caso d’uso. Ma significa che il warehouse è sempre più il luogo dove la verità sul cliente viene modellata, governata e arricchita, e lo stack di attivazione deve rispettarlo.
Cosa lo zero copy non risolve
Qui è dove l’hype va tenuto sotto controllo. Lo zero copy rimuove una classe di debito architetturale. Non rimuove il bisogno di architettura. Un cattivo modello cliente interrogato sul posto è comunque un cattivo modello cliente. Un identity graph frammentato non diventa unificato perché i dati restano in Snowflake. L’ambiguità sul consenso non sparisce perché la piattaforma legge dal warehouse. Una UI marketer-friendly non emerge automaticamente perché una tabella è interrogabile. La latenza non diventa accettabile perché l’architettura è elegante. E nemmeno i costi spariscono: costi di query, performance del warehouse, concorrenza, strategia di caching, ownership dei data product e troubleshooting diventano tutti parte del modello operativo.
Ci sono anche casi d’uso in cui copiare i dati dentro la piattaforma di engagement ha ancora senso. Una parte dello stato del journey appartiene alla CEP. Alcuni attributi di profilo devono essere disponibili con latenza molto bassa. Alcune logiche di personalizzazione sono più facili e più sicure quando la piattaforma possiede il contesto richiesto. Alcune esecuzioni sui canali richiedono stato locale. Alcuni requisiti normativi o operativi possono favorire una replica controllata rispetto alla federazione live. L’obiettivo non è eliminare tutte le copie. L’obiettivo è rendere il copiare intenzionale, che è uno standard molto diverso da quello che molte architetture usano oggi.
La nuova divisione delle responsabilità
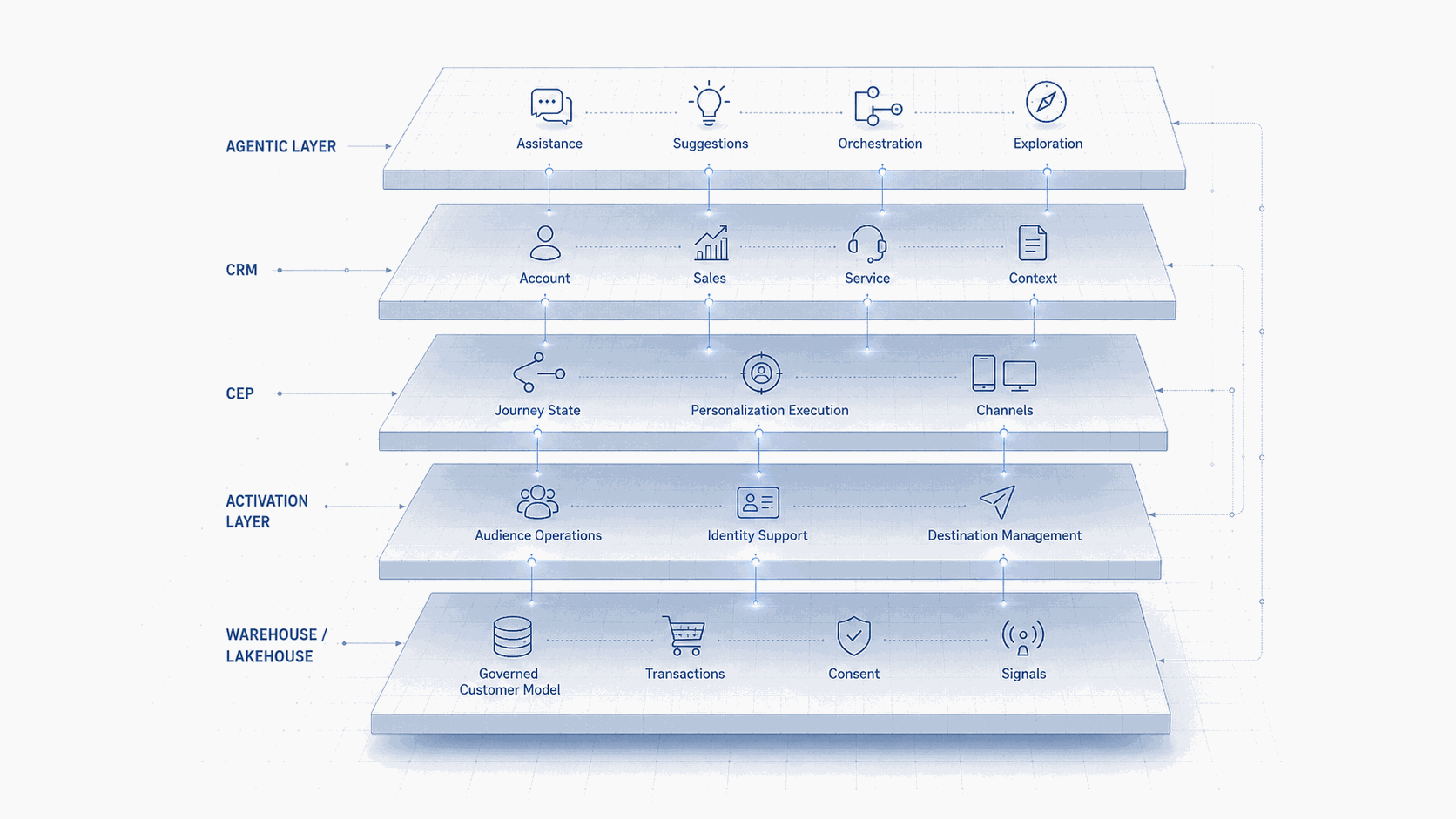
Se lo zero-copy engagement diventa più diffuso, la vera domanda non è se il CDP, la CEP o il warehouse “possieda il cliente”. Quella domanda non è mai stata molto utile. La domanda migliore è quale layer possiede quale responsabilità.
Il warehouse o il lakehouse può possedere il modello cliente governato, lo storico transazionale, l’utilizzo del prodotto, l’evidenza del consenso, le feature predittive e la verità analitica. Il CDP composable o il layer di attivazione può possedere le operazioni sulle audience, il supporto all’identity stitching, il reverse ETL, la gestione delle destination e l’accesso del marketer ai dati modellati nel warehouse. La CEP può possedere lo stato del journey, il coordinamento dei canali, l’assemblaggio del messaggio, la sperimentazione, l’esecuzione della personalizzazione e lo storico delle interazioni. Il CRM può possedere il contesto della relazione commerciale, i processi di sales e service, le strutture degli account e i record operativi. Il layer agentico può possedere sempre più l’assistenza, i suggerimenti di orchestrazione, la generazione di journey, l’esplorazione delle audience e l’accelerazione operativa.
Ma questi confini devono essere espliciti. Se non lo sono, lo zero copy non semplificherà l’architettura. Renderà solo la confusione più veloce.
La domanda che farei
Se dovessi valutare un’architettura di customer engagement oggi, farei una domanda prima di guardare il journey builder: quando una campagna, un journey o un agente prende una decisione, quale versione del cliente sta usando? Non quale piattaforma ha la migliore UI di segmentazione, non quale vendor ha la roadmap AI più forte, non quale CDP ha la demo del profilo più completa. Quale versione del cliente viene usata nel momento della decisione.
Se la risposta è “una copia sincronizzata la notte scorsa”, può essere accettabile per alcune campagne ma non per tutte. Se la risposta è “un modello cliente governato interrogato o referenziato dal warehouse con latenza, permessi e auditabilità chiari”, allora l’architettura si sta muovendo nella direzione giusta.
Il warehouse non sostituisce la piattaforma di engagement, e la piattaforma di engagement non sostituisce il warehouse. Il punto è smettere di costringere ogni layer a fingere di essere l’altro. Lo zero-copy engagement conta perché rende quella separazione realistica: lascia che il warehouse stia più vicino al cervello della campagna senza chiedergli di diventare lo strumento di campagna, e lascia che la CEP si concentri su ciò in cui dovrebbe essere migliore, trasformare il contesto cliente in azione cross-channel tempestiva e governata. L’architettura, come sempre, è la cosa che decide se la promessa diventa utile.
Fonti
Braze
- Note di rilascio del 30 aprile 2026: sync CDI zero-copy per i trigger Canvas
- Personalizzazione zero-copy con CDI
- Introducing Braze CDI Segments: Providing Zero-Copy Access to Your Data Warehouse
Insider One
- Insider One Launches Zero Copy Segmentation for Snowflake-Powered Customer Activation (2 giugno 2026)
- Insider Partners with Snowflake to Power Real-Time Cross-Channel Personalization
- Insider Announces Snowflake Integration
Salesforce
- Data 360: Zero Copy Connectivity
- Data 360 Interoperability Decision Guide
- Zero Copy Data Federation Use Cases and Setup Guide
Adobe
- Engage with Audiences Using Federated Audience Composition
- Federated Audience Composition High-level Architecture and Flow
- Adobe’s Flexible Approach to Data Composability in Real-Time CDP
Hightouch
Twilio Segment
Treasure AI / Treasure Data
Bloomreach
Iterable
- Snowflake + Smart Ingest (Iterable Support Center)
- Snowflake and Iterable Partner for Data Sharing Integration
Snowflake
Se trovi errori o lacune nella copertura, voglio saperlo. Il processo migliora quando l’output viene messo in discussione.