TL;DR: Zero-copy activation is not only about avoiding data duplication. It is about changing where customer truth lives, where decisions are computed, how engagement platforms relate to the warehouse, and increasingly, what agentic marketing systems can actually reason from. The real test is not whether a vendor says “zero copy”, but whether copying becomes an intentional architectural choice rather than the default.
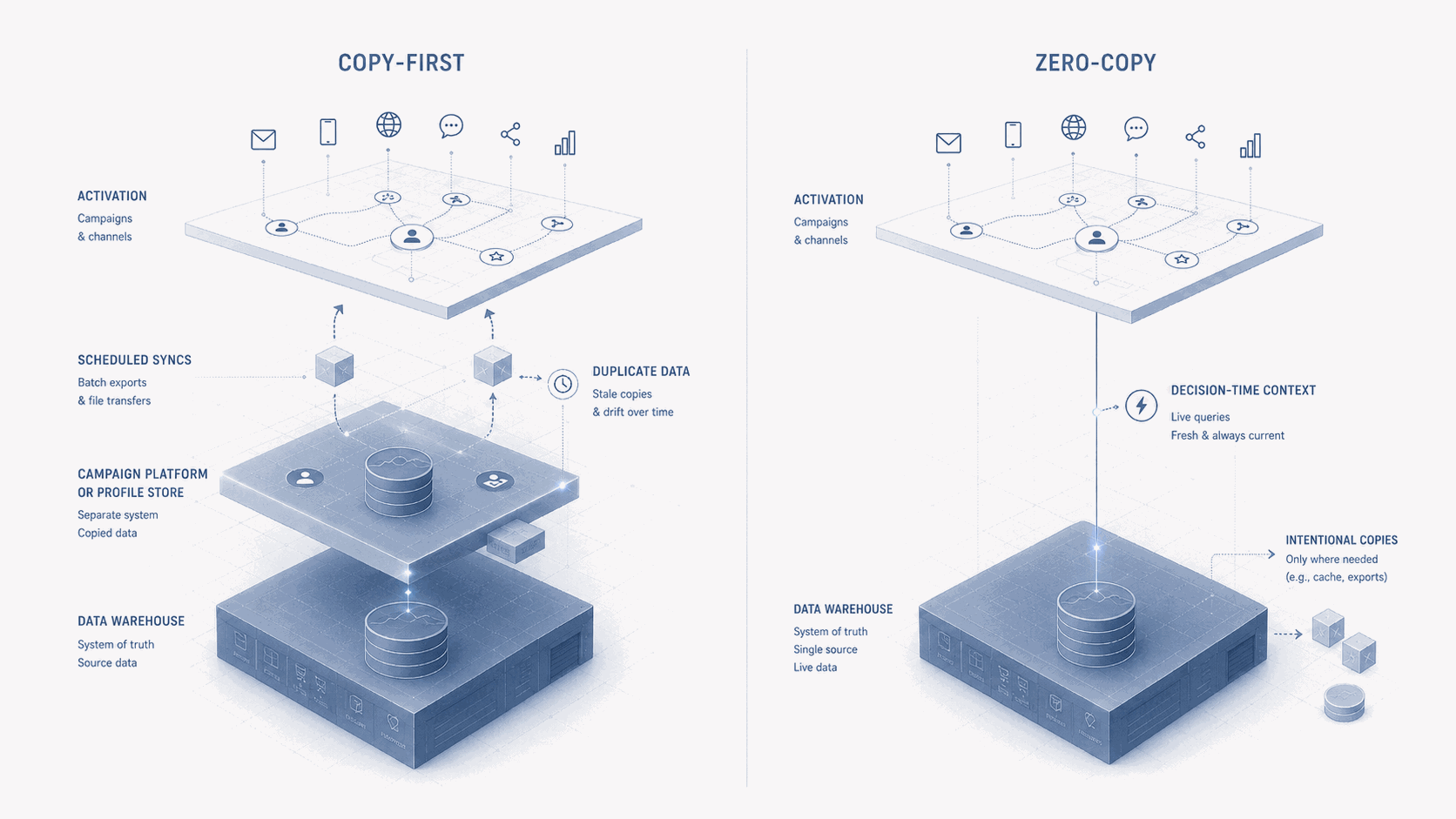
For years, customer engagement architecture has rested on a quiet assumption: before a platform can act on customer data, it must first copy that data into itself. Every copy was introduced for a reason, performance, marketer autonomy, channel execution, vendor lock-in, but each copy also created another place where customer truth could drift.
Consent stale in one system, suppression rules missing in another, product affinity recomputed in the warehouse while the campaign platform was still using yesterday’s value.
That assumption is starting to break, and the direction of change is visible: customer engagement platforms are increasingly trying to activate data where it already lives.
What Zero Copy Actually Means
The phrase “zero copy” is easy to oversell. It does not always mean that no data ever moves, no query result is ever cached, no context is ever materialized, and no activation log is ever stored somewhere else. In practical enterprise architecture, something almost always moves at some point: a query is executed, a result is returned, an audience membership may be materialized, a trigger event may be passed into a journey, and a message interaction is stored for reporting, compliance, debugging or attribution.
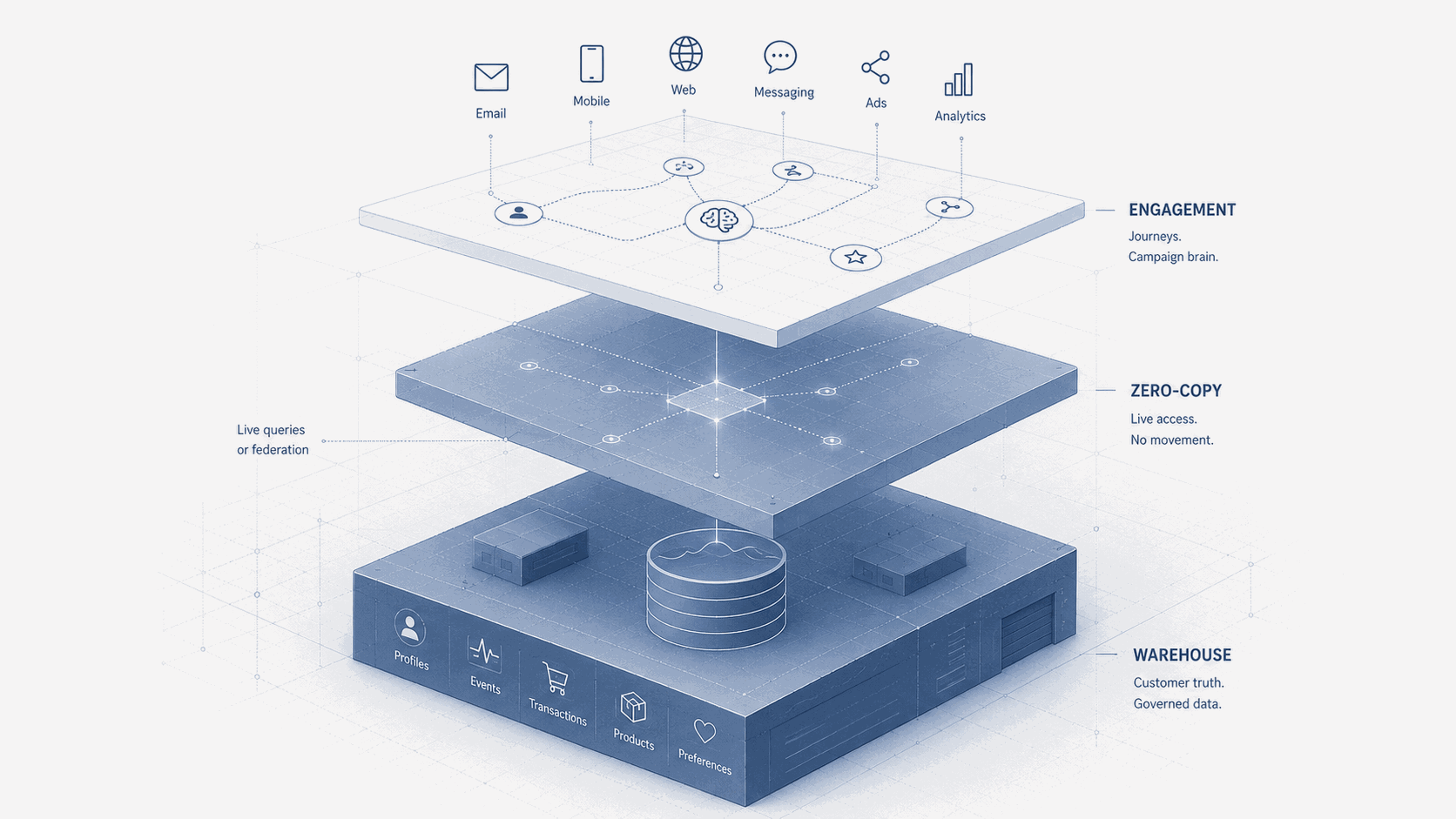
So the useful definition is not theological. Zero copy means that the activation platform does not need to persist a full duplicate of the underlying customer dataset before it can act on it. The warehouse, lakehouse or cloud data platform remains the primary data substrate, and the engagement platform queries, references or receives selected context from that substrate when it needs to personalize, trigger, segment or decide.
That is a meaningful architectural shift, because the old model said: move the data into the platform, then let the platform decide. The new model increasingly says: keep the data where it is governed, and let the platform act on it from there. Those are not the same architecture.
Why This Is Happening Now
Zero copy is not emerging because vendors suddenly discovered that data duplication is inelegant. Architects have known that for years. It is emerging because several pressures are converging at once.
The first is the rise of the cloud data warehouse as the real enterprise system of truth. In many organizations, Snowflake, Databricks, BigQuery or Redshift already contain the most complete view of the customer: transactions, product usage, billing, loyalty, consent, service history, digital behavior, offline events, predictive scores and operational attributes.
The second is the disappointment with some traditional CDP implementations. Many CDPs promised to become the central customer database, but in practice they often became another customer database, sitting beside the warehouse, partially synchronized, expensive to maintain and not always trusted by data teams.
The third is the growth of composable CDP patterns. Tools like Hightouch and Census, along with warehouse-native activation layers, reframed the CDP conversation around a simple idea: if the warehouse already contains the trusted customer model, why rebuild that model somewhere else before activating it?
The fourth is operational pressure on customer engagement platforms. CEPs need to support richer personalization, faster triggering and more complex decisioning without asking every client to duplicate every possible attribute into the platform profile in advance.
The fifth is AI. Agentic marketing systems need access to customer context. If the agentic layer can only see the partial profile stored inside the engagement platform, it will reason from a partial reality. If it can safely query governed warehouse data, the quality of its decisions can improve, provided the governance model is strong enough.
This is why zero copy is not just a data integration topic. It is becoming part of the operating model for customer engagement.
The Vendor Landscape Is a Spectrum, Not a Checkbox
The market is moving in the same general direction, but not every vendor is doing the same thing, and that distinction matters. Some vendors are warehouse-native by design. Some are adding zero-copy access to existing engagement platforms. Some are improving warehouse ingestion, which is useful but still different from zero copy. Some are using the term loosely.
That is why I would avoid treating zero copy as a binary feature. The better question is: what role does the warehouse play in the architecture? A platform that imports from Snowflake on a schedule and a platform that queries Snowflake at decision time can look almost identical in a demo and behave very differently in production. Keep the import-versus-federation distinction in mind through the whole section below, because it is the line that actually separates the categories.
Hightouch and the Warehouse-Native Starting Point
Hightouch is the cleanest expression of the composable CDP pattern. Its architectural premise is that the warehouse is the source of truth and the activation layer should operate around it rather than replacing it. Audience logic, identity work, decisioning and activation are built on top of warehouse data, with downstream tools receiving the outputs they need.
This is different from the classic packaged CDP model. In the classic model, the CDP wants to ingest customer data, unify it, store it, segment it and activate it. In the composable model, the warehouse remains the main customer data environment, while the CDP-like layer provides marketer access, identity capabilities, audience building, reverse ETL, activation and, increasingly, AI-driven decisioning. That difference is not cosmetic: it changes the data ownership model.
Salesforce Data 360 and Adobe: Zero Copy at Suite Scale
Salesforce and Adobe are worth reading together, because both are approaching zero copy not from the CDP side alone, but from the side of a large, integrated experience suite.
Salesforce has made zero-copy connectivity a central part of the Data 360 story. The mechanism is Advanced Query Pushdown: rather than creating full replicas in Data 360’s data lake, it delegates retrieval to the originating warehouse through an optimized pushdown query that returns just the data needed. It supports two federation methods, query federation over JDBC (Snowflake, Databricks, BigQuery, Redshift) and file federation over open standards like Apache Iceberg and Parquet, and it is bi-directional: Salesforce can share insights back to those platforms without copying data. The broader promise is to connect enterprise data to CRM, marketing, service, analytics and agentic workflows without constantly rebuilding pipelines. That is powerful, especially in Salesforce-heavy organizations. Based on public material, however, Salesforce sits closer to the federation-with-materialization end of the spectrum than to pure live query: the architecture is zero-copy in direction but still depends on structured harmonization steps before data becomes fully actionable in marketing execution. The evaluation questions that matter most are: where is context cached, which objects need to be materialized inside Salesforce-controlled structures, and what is the real latency from warehouse update to campaign decision.
Adobe brings the same idea into the Experience Platform world through Federated Audience Composition. The pitch is explicit about the pattern: a zero-copy query model that lets teams build and enrich audiences directly against datasets in Snowflake, Databricks or Redshift without copying the underlying data, so the warehouse stays the system of record and the platform avoids profile bloat. The resulting audience is still fully actionable inside Real-Time CDP and the downstream Adobe channels. For Adobe-certified shops this is a significant shift, because it lets Real-Time CDP behave as the engagement engine over a composable foundation rather than insisting that every attribute be ingested into the profile store first. The same caveat applies as with Salesforce: federation strength depends on connectivity (private link support, governance, latency) and on being honest about which use cases still require materialized profile attributes.
Braze and Zero-Copy Engagement
Braze is interesting because it is not a composable CDP vendor by origin. It is a customer engagement platform, with strong cross-channel orchestration, mobile engagement, event-driven personalization and campaign execution. So when Braze adds zero-copy capability, the signal is different.
Braze already supported Cloud Data Ingestion and CDI Segments, giving teams ways to use warehouse data in Braze workflows. The April 30, 2026 release pushed this further into journey execution with zero-copy CDI Canvas triggers: marketers can trigger Canvases from warehouse or S3 data and pass context fields into the Canvas as personalization properties without persisting those fields on Braze user profiles. Braze does not store a backup of the query results, and the context properties may be retained in internal systems for up to thirty days for operational purposes, which is worth noting for governance reviews but is a different thing from rebuilding the profile.
This does not turn Braze into a warehouse-native CDP. It does something more interesting: it acknowledges that a CEP does not need to own all customer data to be operationally powerful.
Insider One and Zero Copy Segmentation
Insider has moved decisively in this direction, and the clearest signal is recent.
On June 2, 2026, during Snowflake Summit, Insider One launched Zero Copy Segmentation for Snowflake, which builds on its earlier 2025 Secure Data Sharing partnership but goes further into the activation pattern itself. The mechanism is the interesting part: instead of ingesting raw customer data, Insider executes segmentation queries directly on Snowflake and stores only the resulting audience membership for activation. Audiences can be refreshed at send time against the latest available data, and the whole flow operates within Snowflake’s existing security and permission model.
That is close to the cleanest CEP-side expression of the idea this article is about. The platform keeps the raw governed data where it lives, persists only what it needs to act (the membership, not the dataset), and pulls freshness forward to the moment of send rather than the moment of export. Insider frames the high-value cases as real-time behavioral targeting, AI and model-driven segmentation such as propensity or risk-based audiences, and compliance-sensitive activation where data must stay inside governed environments, which is exactly where the import-then-activate model tends to break down. In retail, financial services and travel, where data is large, volatile, sensitive and time-critical, that combination matters. The relevant question was never simply whether a Snowflake integration exists, because many platforms can import from Snowflake. It is whether the platform can use warehouse data as a live operational substrate, and on this evidence Insider sits firmly at the federation end of the spectrum. The honest caveat is that this is a days-old launch announced at a vendor summit, so the pattern is sound but the production evidence is still thin, and in a real evaluation it deserves the same scrutiny as every other claim in this article.
Segment, Treasure AI and the CDP Repositioning
Twilio Segment is moving toward more warehouse-native audience use cases. Advanced Audiences and Linked Audiences point in this direction by letting marketers build audiences from warehouse-connected entity data and aggregated conditions, without asking engineers to precompute every metric in advance. Underneath sits the Data Graph, a semantic layer that defines relationships between the Segment profile and warehouse entities such as accounts, subscriptions, households and products, with results written back to Snowflake, Databricks, BigQuery or Redshift.
Treasure Data, now Treasure AI, is another useful signal, because it explicitly frames composable CDP capabilities around building on top of existing warehouse infrastructure, including live zero-copy connections with Snowflake. The category story is becoming visible: CDPs are no longer only competing to be the place where customer data is stored. They are competing to be the place where customer data becomes usable. That is a different job.
Bloomreach and Iterable: The Difference Between Import and Zero Copy
Bloomreach and Iterable belong together, because both illustrate why the import-versus-zero-copy distinction matters in practice.
Bloomreach’s Snowflake integration makes it easier to bring customer profiles, events and product data from Snowflake into Bloomreach Engagement. For many organizations that is genuinely useful: it can reduce engineering work and improve campaign freshness. But based on the public material I reviewed, the Snowflake story is framed primarily as native import into Bloomreach Engagement, not as a zero-copy-first operating model.
Iterable sits in the same category. Its native warehouse capability, Smart Ingest, imports data from Snowflake into Iterable, and a separate integration handles export back out. The earlier Snowflake Secure Data Sharing partnership added governed data sharing on top, but the center of gravity is still warehouse-connected import, not live federation at decision time.
Neither placement is a criticism. Warehouse-connected is not the same as warehouse-native, and import automation is not the same as zero-copy activation. In real evaluations the distinction matters precisely because both patterns can look similar in a demo and behave differently in production.
Why Zero Copy Matters
The most obvious benefit is reduced duplication, and with it fewer places where customer truth can drift, the problem this article opened on. That is real, but it is not the whole story. The more important benefits are architectural, and they all come back to a single idea: copying becomes a deliberate decision rather than a reflex.
1. Decisions Can Be Fresher
A journey decision is only as good as the data available at the moment the decision is made. That sounds obvious, yet many marketing architectures still run on scheduled exports, batch synchronizations and profile attributes refreshed at fixed intervals. For some use cases that is fine. For others it is not. A customer who has just purchased should not receive an abandoned-cart message because the suppression attribute has not synchronized yet. A customer who opened a high-priority service case should not receive an aggressive upsell because the marketing platform does not know yet. A customer whose consent changed should not remain eligible because the engagement tool is working from a stale copy. Zero-copy patterns do not automatically make everything real time, but they push the architecture closer to decision-time context rather than campaign-preparation context.
2. AI Needs a Better Data Substrate
This is the part I keep coming back to. Agentic marketing is arriving faster than most organizations can govern it. Platforms are adding agents that generate audiences, propose journeys, write content, explain performance and, increasingly, act on behalf of the marketer. But an agent can only reason from what it can see. If it only sees the internal profile inside the CEP, then that profile becomes the agent’s reality, and if the profile is incomplete, stale or disconnected from the enterprise customer model, the agent will operate with false confidence.
Zero copy gives the agentic layer access to a broader, more governed, more current substrate, but only when access is controlled, lineage is understandable, permissions are well designed and the agent’s actions are auditable. Without those conditions, zero copy simply gives the agent a larger surface on which to make mistakes.
3. Platform Evaluation Becomes More Architectural
For years, CEP evaluations focused heavily on visible features: journey builder usability, channels, templates, segmentation UI, experimentation, reporting, AI content generation. Those things still matter.
But zero copy introduces a deeper set of questions that belong in platform selection, not in a late implementation phase. I would now ask:
- Where does identity resolution happen, and where does consent live?
- Where are audience definitions computed?
- Which attributes must be persisted in the platform, and which can be queried at decision time?
- What is the latency between a warehouse update and a campaign action?
- What is cached, where, and for how long?
- Who can create an audience from warehouse data, who approves it, and what does the audit trail show?
These are not secondary implementation details anymore. They are selection criteria.
The Link With Composable CDP
Zero copy and composable CDP are not the same thing, but they belong to the same architectural movement. The composable CDP argument was never only about saving money on CDP licenses. At its best, it was about avoiding an unnecessary second customer database when the organization had already invested heavily in a cloud data platform. The logic was simple: if the warehouse already contains the best customer data, why extract it, reshape it and rebuild it inside a packaged CDP before marketers can use it?
That question has only become more relevant, and what has changed is that the argument is no longer limited to composable CDP vendors. CEPs are adapting to it, suites are adapting to it, CDPs are repositioning around it, and data warehouses and lakehouses are becoming more operational. The market is not saying that every company should replace its CDP with a warehouse-native activation layer, which would be too simplistic. It is saying something more nuanced: the warehouse is becoming hard to ignore as the center of gravity for customer data.
That does not mean the warehouse should do everything. I do not believe the data warehouse should become the journey builder, the email engine, the mobile messaging layer or the marketer interface for every use case. But it does mean the warehouse is increasingly where customer truth is modeled, governed and enriched, and the activation stack has to respect that.
What Zero Copy Does Not Solve
This is where the hype needs to be kept under control. Zero copy removes one class of architectural debt. It does not remove the need for architecture. A bad customer model queried in place is still a bad customer model. A fragmented identity graph does not become unified because the data stays in Snowflake. Consent ambiguity does not disappear because the platform reads from the warehouse. A marketer-friendly UI does not automatically emerge because a table is queryable. Latency does not become acceptable because the architecture is elegant. And costs do not disappear either: query costs, warehouse performance, concurrency, caching strategy, data product ownership and troubleshooting all become part of the operating model.
There are also use cases where copying data into the engagement platform still makes sense. Some journey state belongs in the CEP. Some profile attributes need to be available with very low latency. Some personalization logic is easier and safer when the platform owns the required context. Some channel execution requires local state. Some regulatory or operational requirements may favor controlled replication over live federation. The goal is not to eliminate all copies. The goal is to make copying intentional, which is a very different standard from the one many architectures use today.
The New Responsibility Split
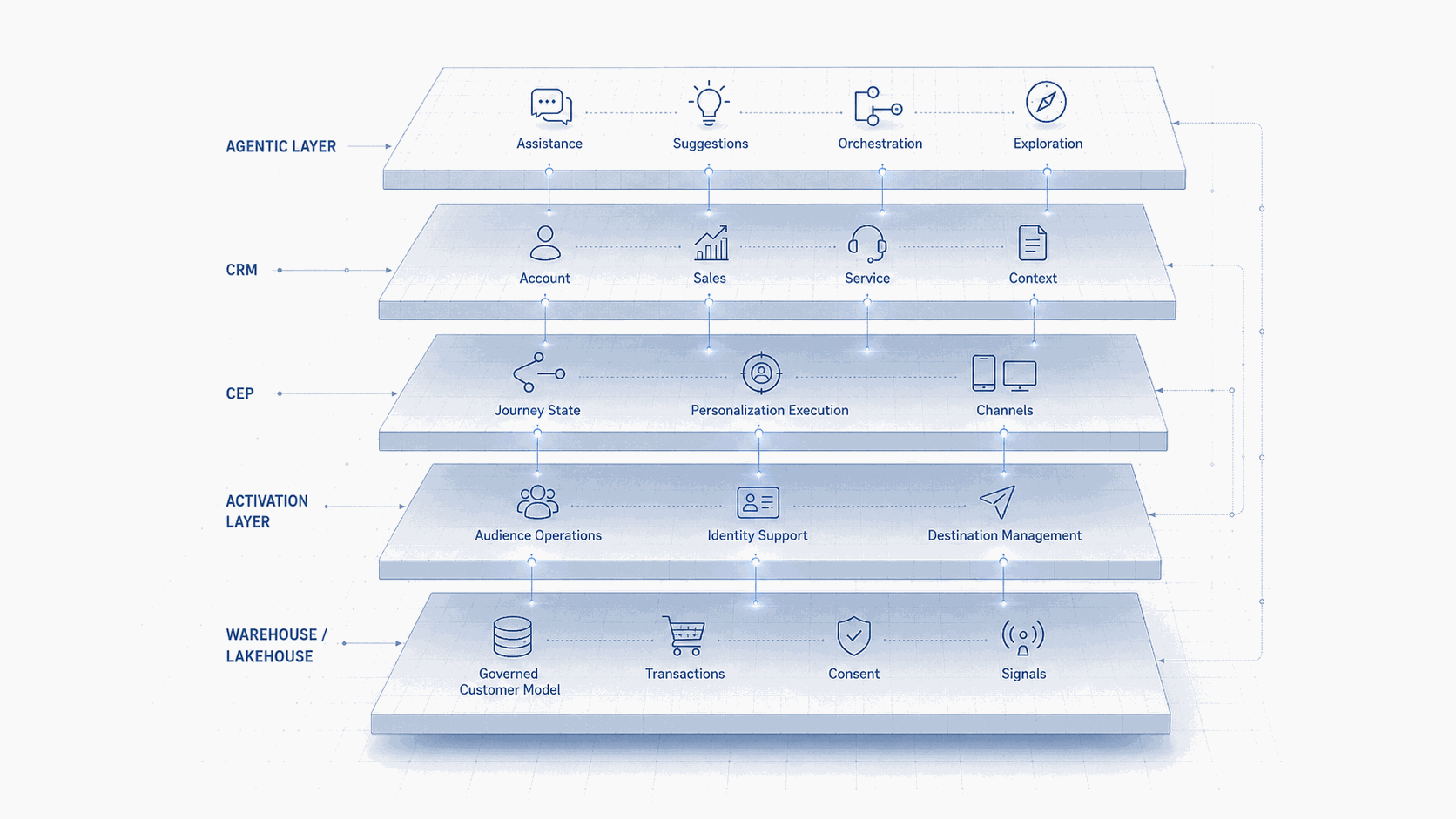
If zero-copy engagement becomes more common, the real question is not whether the CDP, CEP or warehouse “owns the customer.” That question was never very useful. The better question is which layer owns which responsibility.
The warehouse or lakehouse may own the governed customer model, transactional history, product usage, consent evidence, predictive features and analytical truth. The composable CDP or activation layer may own audience operations, identity stitching support, reverse ETL, destination management and marketer access to warehouse-modeled data. The CEP may own journey state, channel coordination, message assembly, experimentation, personalization execution and interaction history. The CRM may own commercial relationship context, sales and service processes, account structures and operational records. The agentic layer may increasingly own assistance, orchestration suggestions, journey generation, audience exploration and operational acceleration.
But these boundaries need to be explicit. If they are not, zero copy will not simplify the architecture. It will only make the confusion faster.
The Question I Would Ask
If I were evaluating a customer engagement architecture today, I would ask one question before looking at the journey builder: when a campaign, journey or agent makes a decision, which version of the customer is it using? Not which platform has the best segmentation UI, not which vendor has the strongest AI roadmap, not which CDP has the most complete profile demo. Which version of the customer is being used at the moment of decision.
If the answer is “a copy synchronized last night,” that may be acceptable for some campaigns but not for all. If the answer is “a governed customer model queried or referenced from the warehouse with clear latency, permissions and auditability,” then the architecture is moving in the right direction.
The warehouse does not replace the engagement platform, and the engagement platform does not replace the warehouse. The point is to stop forcing each layer to pretend it is the other. Zero-copy engagement matters because it makes that separation realistic: it lets the warehouse sit closer to the campaign brain without asking it to become the campaign tool, and it lets the CEP focus on what it should be best at, turning customer context into timely, governed, cross-channel action. The architecture, as usual, is the thing that decides whether the promise becomes useful.
Sources
Braze
- April 30, 2026 Release Notes: Zero-copy CDI syncs for Canvas triggers
- Zero-copy personalization using CDI
- Introducing Braze CDI Segments: Providing Zero-Copy Access to Your Data Warehouse
Insider One
- Insider One Launches Zero Copy Segmentation for Snowflake-Powered Customer Activation (June 2, 2026)
- Insider Partners with Snowflake to Power Real-Time Cross-Channel Personalization
- Insider Announces Snowflake Integration
Salesforce
- Data 360: Zero Copy Connectivity
- Data 360 Interoperability Decision Guide
- Zero Copy Data Federation Use Cases and Setup Guide
Adobe
- Engage with Audiences Using Federated Audience Composition
- Federated Audience Composition High-level Architecture and Flow
- Adobe’s Flexible Approach to Data Composability in Real-Time CDP
Hightouch
Twilio Segment
Treasure AI / Treasure Data
Bloomreach
Iterable
- Snowflake + Smart Ingest (Iterable Support Center)
- Snowflake and Iterable Partner for Data Sharing Integration
Snowflake
If you find errors or gaps in coverage, I want to know. The process improves when the output is challenged.