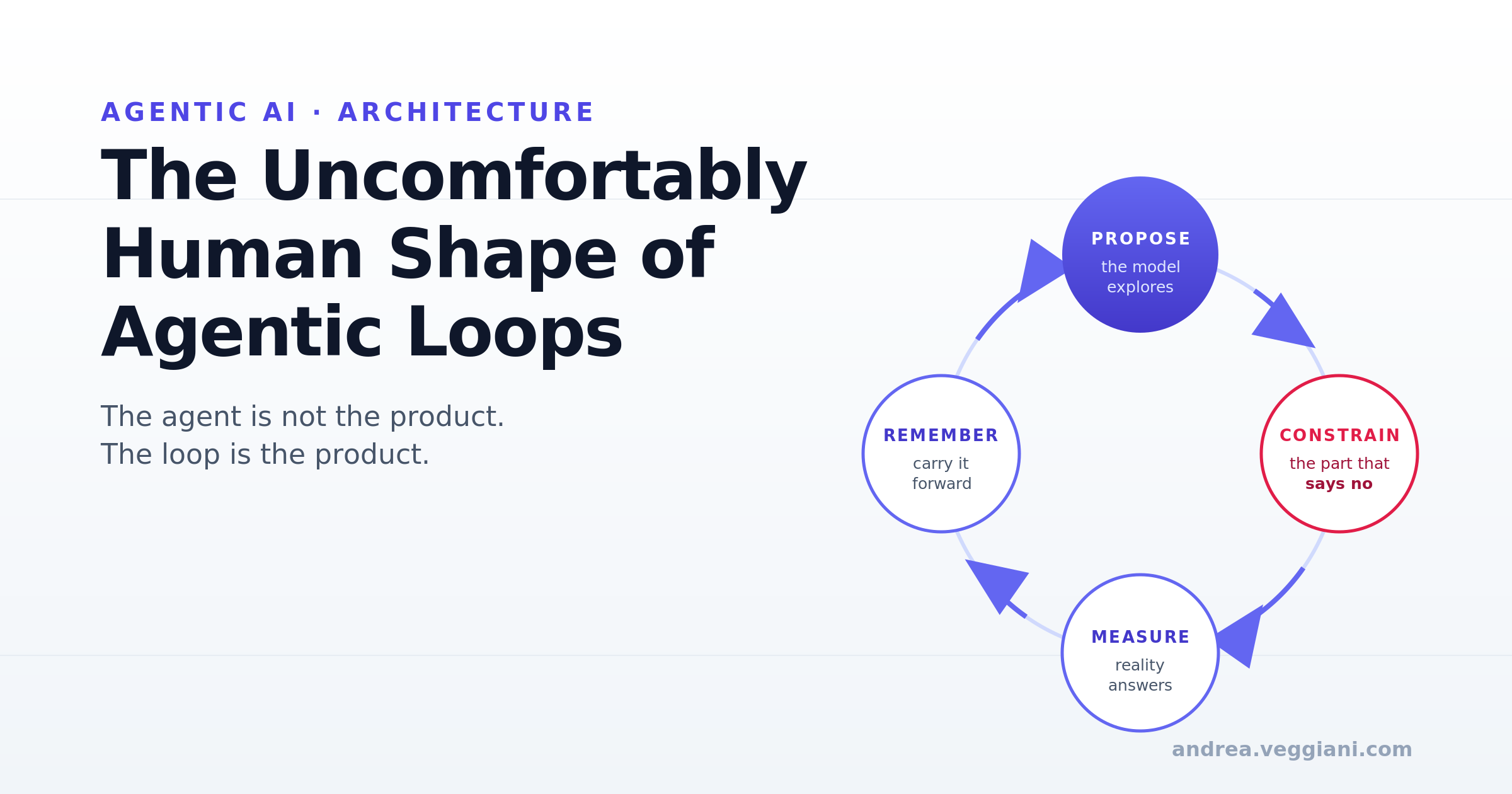
TL;DR: The interesting part of agentic AI is not that the model is smart. It is that the system around the model is starting to look like a cognitive loop: perception, action, feedback, memory, correction, and constraint. The most important piece of that loop turns out to be the part that says no. When we make an unreliable generator useful, we keep rebuilding, piece by piece, something we recognise in ourselves.
A compiler paper should have made this feel less human. It did not.
I recently read Agentic Auto-Scheduling: An Experimental Study of LLM-Guided Loop Optimization, a paper about using an off-the-shelf LLM to guide compiler loop optimization. On paper the topic is beautifully technical and narrow: loop nests, schedules, legality checks, tiling, unrolling, parallelization, speedups. Not the kind of thing that usually produces existential discomfort.
And yet the paper stayed with me, and not because an LLM outperformed a mature optimizer in several cases. That is interesting, but it was not the part that bothered me. What bothered me was the shape of the system.
The LLM proposes an action. The compiler tries it. The environment responds with legality, failure, speedup, slowdown, crash, or success. The LLM receives that feedback, keeps the interaction history, reasons about what happened, and tries again. The system improves not because the model has been fine-tuned, but because the loop around the model lets it learn locally from consequences.
That sounds like software architecture. It also sounds annoyingly human.
I am not saying LLMs have brains. I am not saying compiler feedback is sensation, that a prompt history is consciousness, or that a speedup number is pleasure. That would be the wrong article. What I am saying is narrower and more useful: when we try to make LLM agents reliable, we keep building architectures that resemble some of the functional loops cognitive science has used for decades to describe human learning and action. Prediction, action, error, memory, adjustment, try again.
The unsettling part is not that the machine is becoming human. The unsettling part is that making the machine useful requires us to rebuild, piece by piece, a loop that feels familiar.
That feeling is not new, and it is worth saying so early. Cybernetics named it in the 1940s and 1950s. Wiener and Ashby described purposeful behaviour as a loop of perception, action, error and correction, and they built control systems around exactly that idea. So when an LLM agent starts to look like a feedback loop, it is not becoming human so much as rediscovering a structure we have found before. That is the reassuring part and the unsettling part at once. If the same loop keeps reappearing across eighty years and very different substrates, biological, mechanical, and now statistical, it is probably a real structural attractor rather than a coincidence.
What the COMPILOT paper actually shows
The paper introduces COMPILOT, a framework where an LLM acts as an optimization agent inside a compiler environment. The LLM does not directly rewrite the code, and that distinction matters. Instead, it proposes high-level loop transformations: fuse these loops, tile these dimensions, unroll this inner loop, parallelize this level, reverse or skew where appropriate. The compiler then applies the proposed schedule, checks whether it is valid and legal, generates code, runs it, and reports the measured performance back.
The result is a closed optimization dialogue. The model acts, the compiler observes reality, and the model updates its next attempt based on that observation.
This is the architectural move that makes the paper interesting beyond compilers. The LLM is not trusted to be correct; it is trusted to explore. The compiler is not asked to be creative; it is asked to verify, execute and measure. The intelligence is not inside the model alone, it is distributed across the loop. The system works because it separates roles carefully:
The LLM proposes. It searches a large space of plausible transformation strategies.
The compiler constrains. It checks syntax, legality and semantic preservation.
The runtime measures. It turns speculation into empirical feedback.
The dialogue remembers. It carries successes, failures and partial hypotheses forward.
That division of labour is the whole point. In the reported experiments COMPILOT achieved a geometric mean speedup of 2.66x over the original code on a single run, rising to 3.54x with a best-of-five strategy, and it was competitive with Pluto, a state-of-the-art polyhedral optimizer, reaching 2.94x over Pluto in the best-of-five setting and outperforming it in many cases.
But the more revealing number is not the best speedup, it is the failure rate. Averaged across runs and benchmarks, only 36.1 percent of the model’s proposed schedules were runnable; 31.4 percent were invalid and 32.5 percent illegal. Roughly two-thirds of the propositions were unproductive. In other words, the system succeeds while the model is wrong much of the time.
It is worth being precise about why that works, because the reason does not transfer everywhere. The system tolerates a mostly wrong model because verification is cheap and retries are free. The compiler rejects a bad proposal instantly and at no cost, the loop runs up to thirty iterations, and the best of five independent runs is kept. Being wrong is not expensive here. Hold that thought, because in marketing it is.
There is a second detail worth holding onto. Illegal proposals start near 60 percent on the first turn and fall as the dialogue continues, which the authors read as the model learning from negative feedback inside a single conversation, without any change to its weights.
It is worth being careful with that phrase. The cognitive-science loops I am about to reach for, prediction error in dopamine, predictive processing in cortex, are about updating the model itself, the synapses. COMPILOT does not do that. It corrects within a single conversation and forgets everything once the dialogue ends. So the honest human analogue is closer to working memory and within-task error correction than to learning in the deep sense. That makes the resemblance narrower, not weaker. It is the shape of the loop that recurs, not the machinery underneath it.
That is the lesson. Not “the LLM is a compiler”, but something more portable: an unreliable generator can become useful when it is embedded in a loop with a rigorous environment, structured feedback, memory, and a clear action space. That sentence belongs as much in a MarTech architecture review as it does in a compiler paper.
The uncomfortable resemblance
The resemblance starts with the action-observation loop, and COMPILOT is explicit about it. The LLM receives a problem, forms an analysis, proposes a transformation, receives feedback, and continues. The authors describe the optimization dialogue as both the interface for the agent’s perception and action, and its history as a form of episodic memory. That wording is what makes the paper hard to unsee, because a similar loop sits underneath many accounts of human cognition.
In predictive processing theories, the brain is not a passive receiver of the world. It generates expectations about what it is likely to encounter, compares those expectations with incoming signals, and updates when the difference matters. In reinforcement-learning accounts of dopamine, learning depends on prediction error: better than expected, worse than expected, as expected, and the organism adjusts. In work on episodic memory, memory is not only storage but a way to imagine possible futures, rehearse situations and support planning.
None of these theories maps cleanly onto LLM agents. But they rhyme with the architecture. COMPILOT proposes a transformation before knowing whether it will work, the compiler reports whether reality agreed, and the next proposal is shaped by the mismatch. A human expert does something similar, although with a body, years of experience, sensory grounding, emotion, fatigue, social context and accountability attached.
The point is not identity. The point is pattern.
When a senior engineer optimizes code by hand, they rarely enumerate the full search space. They form a hypothesis, try a move, read the profiler, discard the dead path, keep what worked, and use memory of prior failures to narrow the next attempt. When a marketer tunes a customer journey, the same structure appears: hypothesis, action, measurement, adjustment. A campaign is not only built, it is felt through feedback. Open rate is not truth, but it is a signal. Conversion is not meaning, but it changes the next decision. Customer complaints are not a model, but they update the operating one.
This is why the paper felt less like a compiler paper to me and more like an architectural preview. It shows a general pattern: the agent does not need to be globally intelligent if the loop around it is locally corrective. That is powerful, and it is also where the anxiety enters.
Why it feels human, and why that is not the same as being human
There is a lazy version of this argument, and I want to avoid it. The lazy version says: humans learn from feedback, this system learns from feedback, therefore the system is human-like. That is too thin. A thermostat uses feedback. A compiler heuristic uses feedback. A growth marketer staring at a dashboard uses feedback, sometimes too much. Feedback alone is not the interesting part.
The interesting part is the combination. A symbolic problem representation, where the loop nest is turned into a structured format the model can reason about. A constrained action repertoire, where the model cannot do anything but must choose from a defined set of transformations. An external reality check, where the compiler decides which actions are impossible, unsafe or slow. A memory surface, where the dialogue history carries prior attempts forward. A reasoning ritual, where the model is asked to analyse first and explain each move. And a measurable goal, where the environment returns a performance signal.
That is more than feedback. It is a cognitive scaffold. Not a brain, but an architecture for adaptive behaviour.
And that is what makes the comparison useful, not because it proves anything about machine consciousness, but because it tells us what reliable agentic systems are likely to require. They will need perception surfaces. They will need action boundaries. They will need memory. They will need external checks. They will need goal signals. They will need mechanisms for stopping, retrying, escalating and forgetting.
In other words, the agent is not the product. The loop is the product.
This is the same architecture problem entering MarTech
This is where the compiler paper becomes relevant to the work I actually do. MarTech vendors are now adding agents everywhere: campaign agents, journey agents, audience agents, content agents, optimization agents, support agents, sales agents, analytics agents. Some sit in the marketer’s seat, some sit closer to decisioning, and some will sit behind MCP endpoints, reading and acting on platform objects through standard interfaces.
Most of the market conversation still frames this as a model-capability question. Can the agent build a campaign? Can it generate a segment? Can it write the email? Can it inspect a journey? Can it suggest the next best action? Those are useful questions, but they are not the architecture question. The architecture question is different: what loop is this agent inside?
Because an agent without a loop is only a faster UI. An agent inside a bad loop is a faster way to create unmanaged damage. An agent inside a good loop can become genuinely useful, even when the model itself is imperfect.
COMPILOT is a clean example because the environment is strict. A compiler does not care how confident the LLM sounds. If the transformation is illegal, it is illegal. If the code slows down, it slows down. If the schedule crashes, it crashes. Marketing environments are messier. There is no single compiler that can tell you whether a campaign is legal, ethical, on-brand, compliant, commercially sensible, emotionally appropriate and operationally safe. That is the problem.
It is worth sitting with how inconvenient this is for the analogy. The very thing that makes COMPILOT clean, a strict compiler that behaves like a near-perfect oracle, is exactly what marketing does not have and may never have. The cleanest example of the loop is also the least representative one for my own field. Marketing has no compiler. Its feedback is lossy, delayed, contested and political. Legality is arguable, brand is partly a matter of taste, and the ground truth often arrives weeks later as a complaint or a churn event. So the loop still applies, but in marketing it is a loop without an oracle, and that changes everything about how much autonomy you can safely hand to the agent inside it.

A MarTech agent therefore needs several compilers around it, none of them as crisp as the real one:
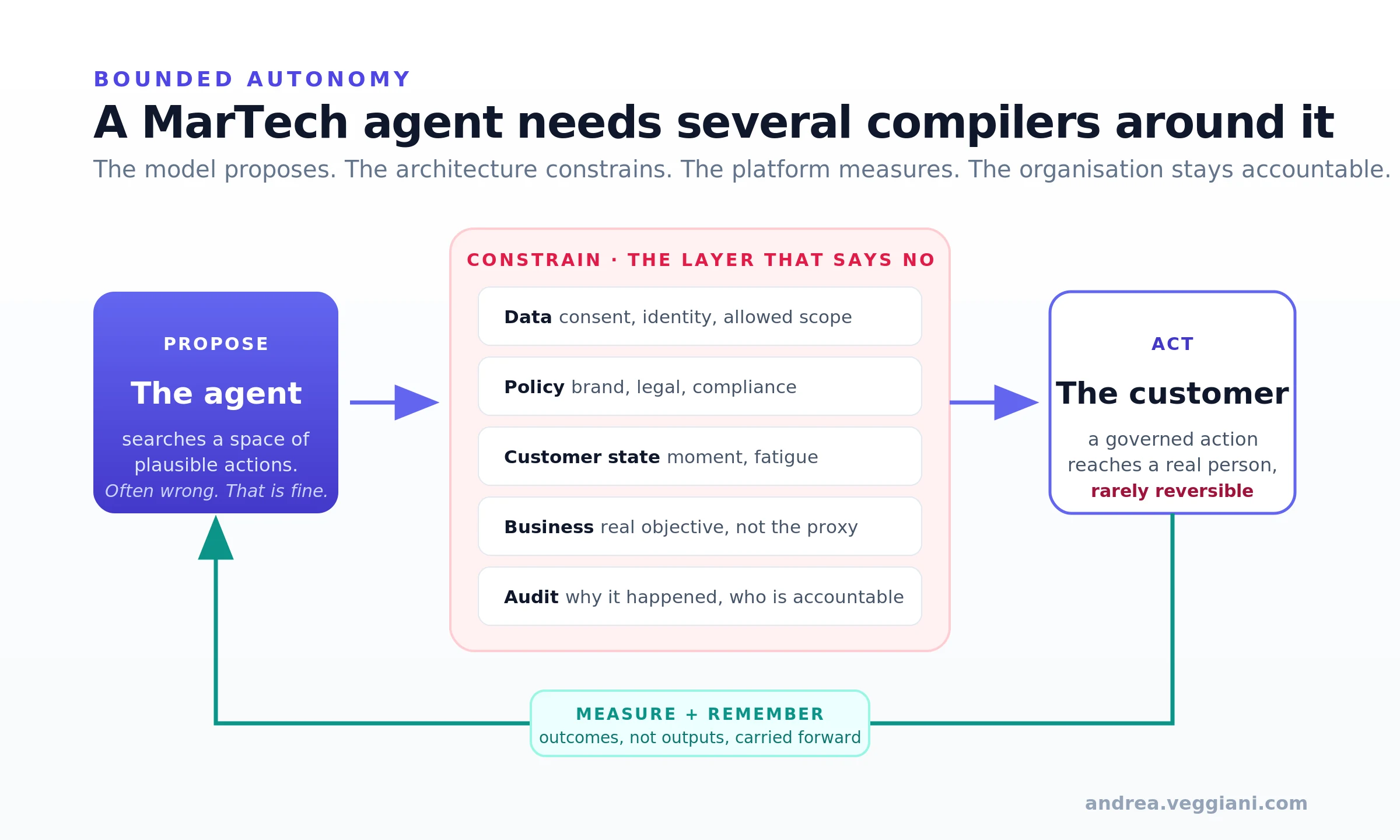
A data compiler. Can the agent see only data it is allowed to use? Is the profile complete enough? Is consent valid? Is identity resolution trustworthy?
A policy compiler. Is this action allowed under brand, legal, compliance and market rules?
A customer-state compiler. Is this the right moment to speak to this person, or is there a service issue, a complaint, a vulnerability signal, a suppression rule or a fatigue threshold that should stop the action?
A business compiler. Is the agent optimizing for the right objective, or for the most measurable proxy?
An audit compiler. Can we reconstruct why this action happened, which data was used, which rule was applied, and who was accountable?
That is the work. The model can propose, the architecture must constrain, the platform must measure, and the organization must remain accountable. Without that, agentic marketing is not intelligence. It is acceleration without brakes.
It is worth being honest about how rare the full set is. Most stacks have one or two of these compilers in a form you would actually trust. Almost none have all five. That makes the list less of an aspiration and more of a diagnostic. The agentic readiness of a platform is roughly how many of these say-no layers exist outside a slide. Count them honestly before you let anything propose on your behalf.
The most important part of the loop is the part that says no
The more I think about COMPILOT, the more I think its most important component is not the LLM. It is the compiler saying no. No, that schedule is invalid. No, that transformation violates dependencies. No, that idea compiled but made performance worse. No, try again.
That is the part many enterprise AI discussions still under-design. We talk about agent autonomy as if autonomy were the valuable thing. It is not. Autonomy without constraint is just unmanaged agency. The valuable thing is bounded autonomy: enough freedom to explore, enough constraint to stay safe, enough feedback to improve, enough memory to avoid repeating the same mistake, and enough observability for humans to trust the process. In COMPILOT, correctness is not delegated to the model. It is delegated to the compiler. That is the key architectural lesson.
But validation only protects you if the agent cannot route around it. A check the agent can edit, skip or argue with is not a constraint, it is a suggestion. So these layers cannot live inside the agent’s prompt or its own reasoning. They have to be enforcement boundaries the platform owns and the agent merely calls: the consent gate in the CDP, the frequency and collision rules in the CEP, the claims and rights checks in the content layer, the audit trail in the data platform. Proposing and enforcing have to be separated, so that a fast agent always meets a slower layer it does not control. That separation, not the cleverness of the model, is what makes the no trustworthy.
If an agent is allowed to generate audiences, the CDP or data warehouse must be able to validate identity, consent, joins, exclusions and suppression logic. If an agent is allowed to build journeys, the CEP must be able to validate channel rules, frequency caps, dependencies, exit criteria, holdouts, experiments and collisions with existing programs. If an agent is allowed to generate content, the content layer must be able to validate brand, claims, regulated language, localization, approvals and rights. And if an agent is allowed to activate customers, the organization must be able to validate outcomes, not only outputs.
This is where I think many agentic roadmaps will break. They will add the proposing layer before they have built the saying-no layer. They will mistake fluent suggestions for governed execution. They will put an agent on top of data they do not trust, journeys they cannot audit and content rules that exist only in people’s heads. Then they will be surprised when the agent behaves exactly as the architecture allowed it to.
The architecture always wins. Especially when the agent is fast.
And there is one asymmetry that should sit at the centre of every agentic design review: reversibility. In COMPILOT a wrong action costs nothing. The bad schedule is discarded, the loop tries again, and nobody is harmed by the attempt. Marketing does not work that way. The email is already sent. The customer is already annoyed. The discount has already taught people to wait. When the cost of a wrong action is low and recoverable, you can let an imperfect agent explore freely. When it is high and irreversible, the loop has to slow down, ask permission, and keep a human inside it. The reversibility of the action should set the autonomy of the agent. That single rule would prevent most of the damage I expect to see.
Why the analogy should make us more careful, not more mystical
I do not think the useful conclusion is that LLM agents are becoming conscious. That is not a claim I can make, and not one I need. The useful conclusion is that the same loop keeps appearing because it solves a real problem. A static model is brittle in a dynamic environment. A model with tools is more useful. A model with tools and feedback is more adaptive. A model with tools, feedback, memory and constraints becomes operational. That progression is the story of agentic AI.
It is also why the human analogy feels unavoidable. We recognise the shape because we live inside a version of it. We act before we know everything. We learn through consequence. We remember failures unevenly. We generalise from too few examples. We overfit to recent feedback. We stop too early when a good-enough answer appears. We need external systems, other people, tools, rules and institutions to keep us from turning every plausible thought into action.
That last point matters. Human cognition is not reliable because the brain is perfect. It is reliable enough, when it is reliable, because it is embedded in scaffolding: language, notebooks, dashboards, peer review, regulation, rituals, checklists, institutions, deadlines, contracts, other people saying no. Good agentic systems will need the same kind of scaffolding. Not the same biological machinery, but the same architectural humility.
The question I would ask in every agentic platform evaluation
The more agents enter MarTech, the less useful it becomes to ask only what the agent can do. A better question is: what does the agent learn from, and who decides whether that lesson is correct?
For a compiler benchmark the answer is relatively clean: legality checks and measured runtime. For marketing it is not. A campaign that gets more clicks may be worse for customer trust. A journey that drives more conversions may increase complaint rate. A discounting agent may improve short-term revenue while training customers to wait. A churn agent may target vulnerable customers in ways that are commercially effective and ethically indefensible. A content agent may produce copy that is accurate enough to pass a casual review and wrong enough to create compliance risk. The feedback signal is never neutral.
This is why the agentic layer cannot be evaluated separately from measurement architecture. What is the reward? What is the penalty? What is excluded from optimization? Which outcomes require human review? Which actions are reversible? Which actions are forbidden? Which signals are trusted, and which are only proxies? Who owns the answer?
This is where the uncomfortable human resemblance becomes practically important. We also optimize against incomplete signals. We also mistake proxies for truth. We also learn the wrong lesson when the environment rewards the wrong behaviour. The difference is that agents can do it faster, more consistently and at larger scale. That is not a reason to avoid them. It is a reason to architect them properly.
Closing
The COMPILOT paper is about compilers. I read it as a paper about the future of agentic systems, not because every domain is loop optimization, but because the pattern is portable: a generative agent inside a constrained environment, acting through a limited repertoire, learning from feedback, carrying memory forward, and improving without changing its weights.
That pattern will show up everywhere. In development tools, in analytics, in customer service, in marketing operations, in journey orchestration, in content supply chains, in decisioning systems that do not wait for a human to draw every branch. The model will get most of the attention. The loop will do most of the work, and the loop is what we need to design, govern and audit.
A few years ago, AI mostly felt like a new interface to knowledge. Now it is becoming a new interface to action, and that is a much bigger shift. Once a system can act, feedback stops being an analytics feature and becomes part of cognition. Memory stops being context management and becomes operational history. Governance stops being a policy document and becomes the shape of the possible.
That is why this feels uncomfortably human. Not because the machine is like us in any complete sense, but because, when we make it useful, we give it a small, engineered version of something we recognise in ourselves: the capacity to try, fail, remember, adjust and try again.
That should not make us mystical. It should make us careful.
Sources
LLM agents, feedback loops and compiler optimization
- Merouani, Kara Bernou, Baghdadi - Agentic Auto-Scheduling: An Experimental Study of LLM-Guided Loop Optimization - The COMPILOT paper that prompted this reflection. Peer-reviewed and published at PACT 2025, and also indexed on IEEE Xplore and the ACM Digital Library.
- Yao et al. - ReAct: Synergizing Reasoning and Acting in Language Models - Foundational work on interleaving reasoning, action and environmental feedback in language-model agents.
- Google Research - ReAct: Synergizing Reasoning and Acting in Language Models - Accessible summary of the ReAct pattern and its action-feedback loop.
- Shinn et al. - Reflexion: Language Agents with Verbal Reinforcement Learning - Language agents that improve through feedback, reflection and episodic memory without updating model weights.
- Park et al. - Generative Agents: Interactive Simulacra of Human Behavior - Agent architecture based on observation, memory, reflection and planning.
- Kulveit, von Stengel, Leventov - Predictive Minds: LLMs as Atypical Active Inference Agents - A direct attempt to interpret LLMs through an active-inference lens. Useful, but I would treat it as conceptual rather than settled science.
Control theory and cybernetics
- Norbert Wiener - Cybernetics: Or Control and Communication in the Animal and the Machine (1948) - The original account of purposeful behaviour as a feedback loop of perception, action, error and correction.
- W. Ross Ashby - Design for a Brain: The Origin of Adaptive Behaviour (1952) - Adaptive behaviour modelled as a system seeking stability through feedback, the intellectual ancestor of the loops in this article.
Cognitive science and neuroscience references
- Bubic, von Cramon, Schubotz - Prediction, Cognition and the Brain - Review of prediction as a central organizing concept in cognition.
- Friston - Free-energy and the Brain - Foundational formulation of perception, action and learning through free-energy minimization.
- Schultz - Dopamine Reward Prediction Error Coding - Review of reward prediction error as a mechanism for learning.
- Schacter et al. - The Future of Memory: Remembering, Imagining, and the Brain - Work on memory as a system for imagining future events and supporting planning.


