Questo articolo è una traduzione assistita dall’AI dell’originale in inglese, revisionata dall’autore.
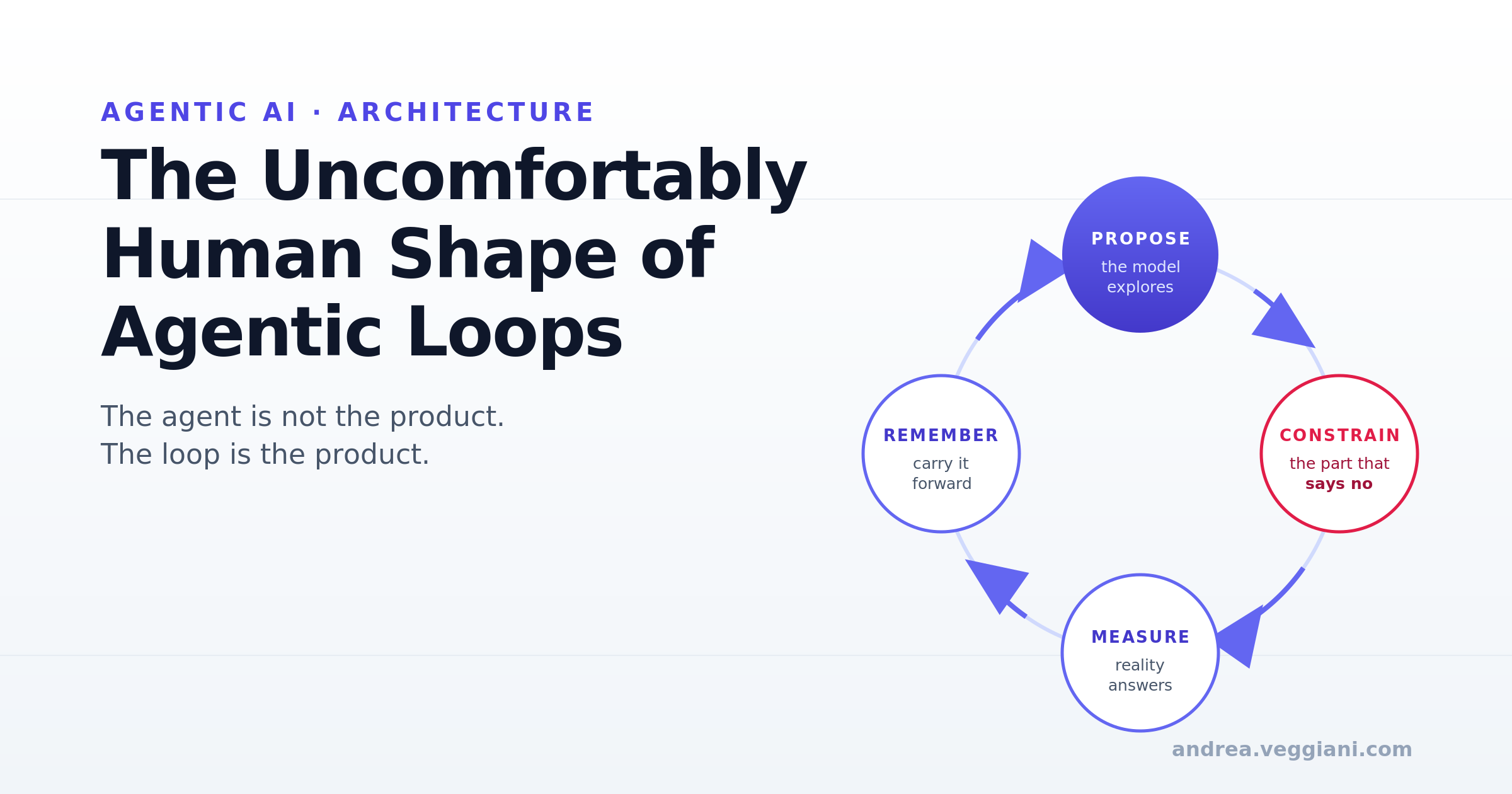
TL;DR: La parte interessante dell’AI agentiva non è che il modello sia intelligente. È che il sistema attorno al modello comincia a somigliare a un loop cognitivo: percezione, azione, feedback, memoria, correzione e vincolo. Il pezzo più importante di quel loop si rivela essere la parte che dice no. Quando rendiamo utile un generatore inaffidabile, continuiamo a ricostruire, pezzo dopo pezzo, qualcosa che riconosciamo in noi stessi.
Un paper su un compiler avrebbe dovuto rendere tutto questo meno umano, ma non è questo il caso.
Di recente ho letto Agentic Auto-Scheduling: An Experimental Study of LLM-Guided Loop Optimization, un paper sull’uso di un LLM pronto all’uso per guidare l’ottimizzazione dei loop in un compiler. Sulla carta l’argomento è splendidamente tecnico e circoscritto: loop nest, schedule, controlli di legalità, tiling, unrolling, parallelizzazione, speedup. Non il genere di cosa che di solito produce disagio esistenziale.
Eppure quel paper mi è rimasto addosso, e non perché un LLM abbia battuto un ottimizzatore maturo in diversi casi. È interessante, ma non è la parte che mi ha turbato. Ciò che mi ha turbato è la forma del sistema.
LLM propone un’azione. Il compiler la prova. L’ambiente risponde con legalità, fallimento, speedup, rallentamento, crash o successo. LLM riceve quel feedback, conserva la storia dell’interazione, ragiona su cosa è successo e riprova. Il sistema migliora non perché il modello sia stato messo a punto con il fine-tuning, ma perché il loop attorno al modello gli permette di imparare localmente dalle conseguenze.
Sembra architettura software. Ma suona anche fastidiosamente umano.
Non sto dicendo che gli LLM abbiano un cervello. Non sto dicendo che il feedback di un compiler sia sensazione, che una cronologia di prompt sia coscienza, o che un numero di speedup sia piacere. Quello sarebbe un altro articolo e sicuramente non sarebbe scritto da me. Quello che dico è più ristretto e più utile: quando proviamo a rendere affidabili gli agenti LLM, continuiamo a costruire architetture che somigliano ad alcuni dei loop funzionali che le scienze cognitive usano da decenni per descrivere l’apprendimento e l’azione umani. Previsione, azione, errore, memoria, aggiustamento, riprova.
La parte inquietante non è che la macchina stia diventando umana. La parte inquietante è che renderla utile ci impone di ricostruire, pezzo dopo pezzo, un loop che ci risulta familiare.
Questa sensazione non è nuova, e vale la pena dirlo subito. La cibernetica le aveva già dato un nome negli anni Quaranta e Cinquanta. Wiener e Ashby descrivevano il comportamento finalizzato come un loop di percezione, azione, errore e correzione, e costruivano sistemi di controllo proprio attorno a quell’idea. Così, quando un agente LLM comincia a somigliare a un loop di feedback, non sta diventando umano: sta piuttosto riscoprendo una struttura che abbiamo già incontrato. È la parte rassicurante e quella inquietante allo stesso tempo. Se lo stesso loop continua a ricomparire nell’arco di ottant’anni e su substrati molto diversi, biologici, meccanici e ora statistici, probabilmente è un vero attrattore strutturale, non una coincidenza.
Cosa mostra davvero il paper COMPILOT
Il paper introduce COMPILOT, un framework in cui un LLM agisce come agente di ottimizzazione dentro l’ambiente di un compiler. L’LLM non riscrive direttamente il codice, e questa distinzione conta. Propone invece trasformazioni di loop ad alto livello: fondi questi loop, applica il tiling a queste dimensioni, fai l’unrolling di questo loop interno, parallelizza questo livello, inverti o applica lo skew dove opportuno. Il compiler poi applica lo schedule proposto, verifica se è valido e legale, genera il codice, lo esegue e riporta indietro la performance misurata.
Il risultato è un dialogo di ottimizzazione chiuso. Il modello agisce, il compiler osserva la realtà, e il modello aggiorna il tentativo successivo sulla base di quell’osservazione.
È questa la mossa architetturale che rende il paper interessante oltre i compiler. Al LLM non si chiede di essere corretto; gli si chiede di esplorare. Al compiler non si chiede di essere creativo; gli si chiede di verificare, eseguire e misurare. L’intelligenza non è solo dentro il modello, è distribuita lungo il loop. Il sistema funziona perché separa con cura i ruoli:
L’LLM propone. Cerca in un ampio spazio di strategie di trasformazione plausibili.
Il compiler vincola. Controlla sintassi, legalità e preservazione della semantica.
Il runtime misura. Trasforma la speculazione in feedback empirico.
Il dialogo ricorda. Porta avanti successi, fallimenti e ipotesi parziali.
Quella divisione del lavoro è tutto il punto. Negli esperimenti riportati COMPILOT ha ottenuto uno speedup di media geometrica di 2,66x rispetto al codice originale in una singola esecuzione, salendo a 3,54x con una strategia best-of-five, ed è risultato competitivo con Pluto, un ottimizzatore poliedrico allo stato dell’arte, raggiungendo 2,94x rispetto a Pluto nella configurazione best-of-five e superandolo in molti casi.
Ma il numero più rivelatore non è lo speedup migliore, è il tasso di fallimento. Mediando su esecuzioni e benchmark, solo il 36,1 percento degli schedule proposti dal modello era eseguibile; il 31,4 percento era invalido e il 32,5 percento illegale. Circa due terzi delle proposte erano improduttive. In altre parole, il sistema ha successo mentre il modello sbaglia gran parte delle volte.
Vale la pena essere precisi sul perché funzioni, perché la ragione non si trasferisce ovunque. Il sistema tollera un modello per lo più sbagliato perché la verifica è economica e i ritentativi sono gratuiti. Il compiler rifiuta una proposta cattiva all’istante e a costo zero, il loop gira fino a trenta iterazioni, e si tiene il migliore di cinque esecuzioni indipendenti. Sbagliare qui non costa caro. Tieni a mente questo punto.
C’è un secondo dettaglio da tenere a mente. Le proposte illegali partono vicino al 60 percento al primo turno e calano man mano che il dialogo prosegue, cosa che gli autori leggono come il modello che impara dal feedback negativo all’interno di una singola conversazione, senza alcuna modifica ai suoi pesi.
Vale la pena usare cautela con quella frase. I loop delle scienze cognitive a cui sto per appellarmi, l’errore di previsione nella dopamina, il predictive processing nella corteccia, riguardano l’aggiornamento del modello stesso, delle sinapsi. COMPILOT non fa questo. Corregge all’interno di una singola conversazione e dimentica tutto una volta che il dialogo finisce. Quindi l’analogo umano onesto è più vicino alla memoria di lavoro e alla correzione dell’errore entro il compito che all’apprendimento in senso profondo. Questo rende la somiglianza più ristretta, non più debole. È la forma del loop a ricorrere, non il meccanismo che le sta sotto.
Questa è la lezione. Non “LLM è un compiler”, ma qualcosa di più trasferibile: un generatore inaffidabile può diventare utile quando è inserito in un loop con un ambiente rigoroso, feedback strutturato, memoria e uno spazio d’azione chiaro. Quella frase appartiene tanto a una review di architettura MarTech quanto a un paper sui compiler.
La somiglianza scomoda
La somiglianza inizia con il loop azione-osservazione, e COMPILOT lo dichiara esplicitamente. LLM riceve un problema, formula un’analisi, propone una trasformazione, riceve feedback e prosegue. Gli autori descrivono il dialogo di ottimizzazione sia come l’interfaccia per la percezione e l’azione dell’agente, sia, nella sua storia, come una forma di memoria episodica. È questa formulazione a rendere il paper difficile da dimenticare, perché un loop simile sta alla base di molte spiegazioni della cognizione umana.
Nelle teorie del predictive processing, il cervello non è un ricettore passivo del mondo. Genera aspettative su ciò che è probabile incontrare, confronta quelle aspettative con i segnali in arrivo e si aggiorna quando la differenza conta. Nelle spiegazioni dell’apprendimento basate sulla dopamina, l’apprendimento dipende dall’errore di previsione: meglio del previsto, peggio del previsto, come previsto, e l’organismo si aggiusta. Nei lavori sulla memoria episodica, la memoria non è solo archiviazione ma un modo per immaginare futuri possibili, provare situazioni e supportare la pianificazione.
Nessuna di queste teorie si applica in modo pulito agli agenti LLM. Ma fanno rima con l’architettura. COMPILOT propone una trasformazione prima di sapere se funzionerà, il compiler riferisce se la realtà è stata d’accordo, e la proposta successiva è plasmata dallo scarto. Un esperto umano fa qualcosa di simile, anche se con un corpo, anni di esperienza, ancoraggio sensoriale, emozione, stanchezza, contesto sociale e responsabilità allegati.
Il punto non è l’identità. Il punto è il pattern.
Quando un ingegnere senior ottimizza il codice a mano, raramente enumera l’intero spazio di ricerca. Formula un’ipotesi, prova una mossa, legge il profiler, scarta il percorso morto, tiene ciò che ha funzionato e usa la memoria dei fallimenti precedenti per restringere il tentativo successivo. Quando un marketer mette a punto un customer journey, compare la stessa struttura: ipotesi, azione, misurazione, aggiustamento. Una campagna non viene solo costruita, viene percepita attraverso il feedback. L’open rate non è la verità, ma è un segnale. La conversione non è un significato, ma cambia la decisione successiva. I reclami dei clienti non sono un modello, ma aggiornano quello operativo.
È per questo che il paper mi è sembrato meno un paper sui compiler e più un’anteprima architetturale. Mostra un pattern generale: l’agente non ha bisogno di essere globalmente intelligente se il loop attorno a lui è localmente correttivo. È potente, ed è anche il punto in cui compare la mia inquietudine.
Perché sembra umano, e perché non è la stessa cosa che esserlo
C’è una versione che si può vendere facile di questo argomento, e voglio evitarla. La versione dice: gli esseri umani imparano dal feedback, questo sistema impara dal feedback, quindi il sistema è simile a un essere umano. Ovviamente non è così Un termostato usa il feedback. Un’euristica di un compiler usa il feedback. Un growth marketer che fissa una dashboard usa il feedback, a volte troppo. Il feedback da solo non è la parte interessante.
La parte interessante è la combinazione. Una rappresentazione simbolica del problema, in cui il loop nest viene trasformato in un formato strutturato su cui il modello può ragionare. Un repertorio d’azione vincolato, in cui il modello non può fare qualsiasi cosa ma deve scegliere da un insieme definito di trasformazioni. Un controllo esterno con la realtà, in cui il compiler decide quali azioni siano impossibili, non sicure o lente. Una superficie di memoria, in cui la storia del dialogo porta avanti i tentativi precedenti. Un rituale di ragionamento, in cui al modello si chiede prima di analizzare e poi di spiegare ogni mossa. E un obiettivo misurabile, in cui l’ambiente restituisce un segnale di performance.
Questo è più del feedback. È un’impalcatura cognitiva. Non un cervello, ma un’architettura per il comportamento adattivo.
Ed è questo che rende utile il confronto, non perché provi qualcosa sulla coscienza delle macchine, ma perché ci dice cosa è probabile che richiedano i sistemi agentici affidabili. Avranno bisogno di superfici di percezione. Avranno bisogno di confini d’azione. Avranno bisogno di memoria. Avranno bisogno di controlli esterni. Avranno bisogno di segnali di obiettivo. Avranno bisogno di meccanismi per fermarsi, riprovare, fare escalation e dimenticare.
In altre parole, l’agente non è il prodotto. Il prodotto è il loop.
È lo stesso problema di architettura che sta entrando nel MarTech
È qui che il paper sui compiler diventa rilevante per il lavoro che faccio davvero. I vendor MarTech stanno ora aggiungendo agenti ovunque: agenti di campagna, agenti di journey, agenti di audience, agenti di contenuto, agenti di ottimizzazione, agenti di supporto, agenti di vendita, agenti di analytics. Alcuni siedono al posto del marketer, alcuni più vicini al decisioning, e alcuni siederanno dietro endpoint MCP, leggendo e agendo sugli oggetti della piattaforma attraverso interfacce standard.
Gran parte della conversazione di mercato inquadra ancora tutto questo come una questione di capacità del modello. L’agente sa costruire una campagna? Sa generare un segmento? Sa scrivere l’email? Sa ispezionare un journey? Sa suggerire la next best action? Sono domande utili, ma non sono la domanda di architettura. La domanda di architettura è diversa: dentro quale loop si trova questo agente?
Perché un agente senza loop è solo una UI più veloce. Un agente dentro un loop cattivo è un modo più veloce di creare danni non gestiti. Un agente dentro un loop buono può diventare davvero utile, anche quando il modello in sé è imperfetto.
COMPILOT è un esempio pulito perché l’ambiente è rigido. Un compiler non si cura di quanto sicuro suoni l’LLM. Se la trasformazione è illegale, è illegale. Se il codice rallenta, rallenta. Se lo schedule va in crash, va in crash. Gli ambienti del marketing sono più disordinati. Non esiste un singolo compiler in grado di dirti se una campagna è legale, etica, on-brand, conforme, commercialmente sensata, emotivamente appropriata e operativamente sicura. È questo il problema.
Vale la pena soffermarsi su quanto questo sia scomodo per l’analogia. Proprio ciò che rende COMPILOT pulito, un compiler rigido che si comporta come un oracolo quasi perfetto, è esattamente ciò che il marketing non ha e forse non avrà mai. L’esempio più pulito del loop è anche il meno rappresentativo per il mio campo. Il marketing non ha un compiler. Il suo feedback è lossy, ritardato, contestato e politico. La legalità è opinabile, il brand è in parte una questione di gusto, e la verità di fatto spesso arriva settimane dopo sotto forma di reclamo o di evento di churn. Quindi il loop si applica ancora, ma nel marketing è un loop senza oracolo, e questo cambia tutto rispetto a quanta autonomia puoi affidare con sicurezza all’agente che ci sta dentro.

Un agente MarTech ha perciò bisogno di diversi compiler attorno a sé, nessuno netto quanto quello vero:
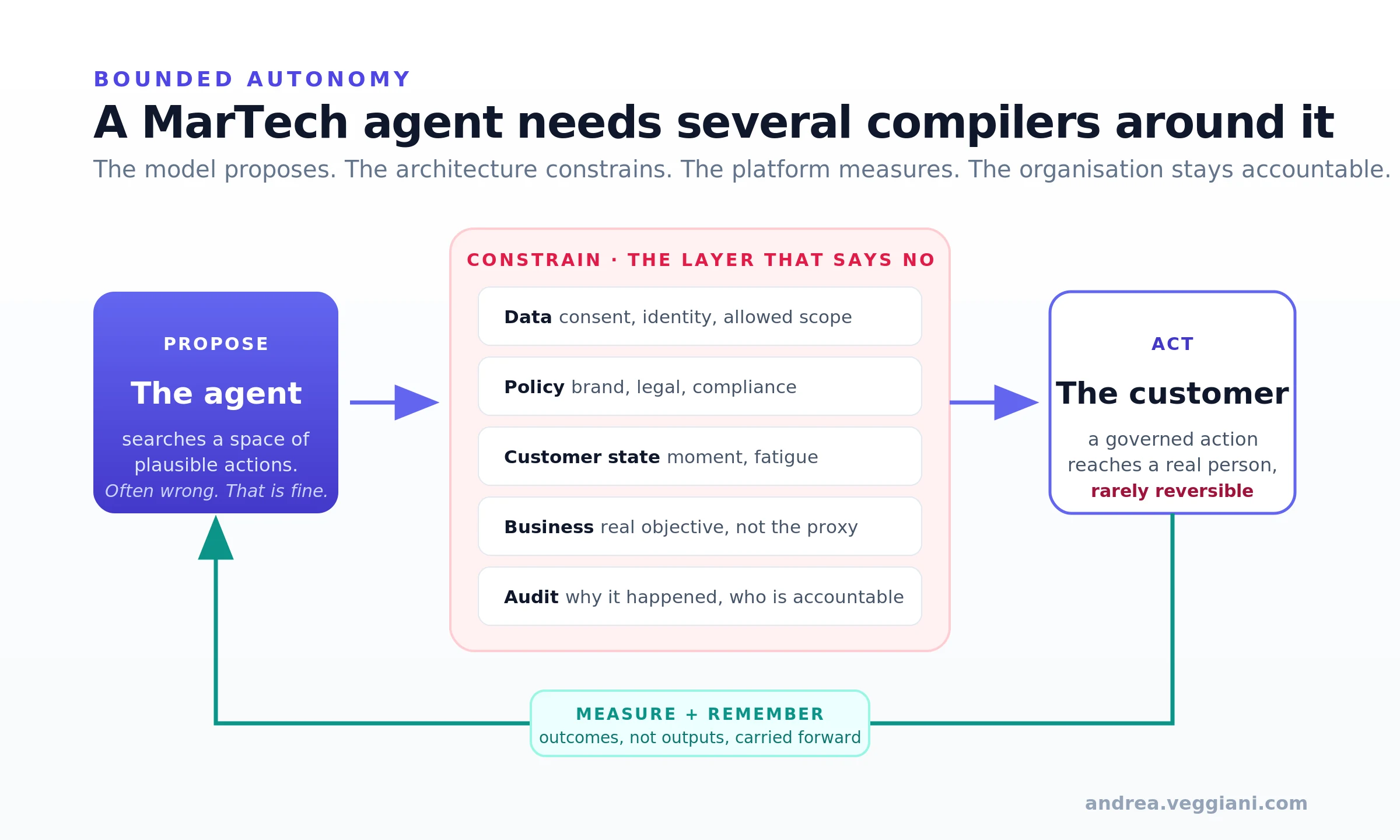
Un compiler dei dati. L’agente può vedere solo i dati che gli è consentito usare? Il profilo è abbastanza completo? Il consenso è valido? La identity resolution è affidabile?
Un compiler delle policy. Questa azione è consentita dalle regole di brand, legali, di compliance e di mercato?
Un compiler dello stato del cliente. È il momento giusto per parlare a questa persona, oppure c’è un problema di servizio, un reclamo, un segnale di vulnerabilità, una regola di soppressione o una soglia di fatigue che dovrebbe fermare l’azione?
Un compiler di business. L’agente sta ottimizzando per l’obiettivo giusto, o per la proxy più misurabile?
Un compiler di audit. Possiamo ricostruire perché questa azione è avvenuta, quali dati sono stati usati, quale regola è stata applicata e chi era responsabile?
Questo è il lavoro. Il modello può proporre, l’architettura deve vincolare, la piattaforma deve misurare e l’organizzazione deve restare responsabile. Senza questo, il marketing agentico non è intelligenza. È accelerazione senza freni.
Vale la pena essere onesti su quanto sia raro avere l’insieme completo. La maggior parte degli stack ne ha uno o due in una forma di cui ti fideresti davvero. Quasi nessuno li ha tutti e cinque. Questo rende l’elenco meno un’aspirazione e più una diagnosi. La maturità agentica di una piattaforma è all’incirca quanti di questi layer del no esistono al di fuori di una slide.
La parte più importante del loop è quella che dice no
Più penso a COMPILOT, più credo che il suo componente più importante non sia l’LLM. È il compiler che dice no. No, quello schedule è invalido. No, quella trasformazione viola le dipendenze. No, quell’idea compilava ma ha peggiorato la performance. No, riprova.
È la parte che molte discussioni sull’AI enterprise progettano ancora male. Parliamo di autonomia dell’agente come se l’autonomia fosse la cosa di valore. Non lo è. Autonomia senza vincolo è solo agency non gestita. La cosa di valore è l’autonomia limitata: abbastanza libertà per esplorare, abbastanza vincolo per restare al sicuro, abbastanza feedback per migliorare, abbastanza memoria per evitare di ripetere lo stesso errore, e abbastanza osservabilità perché gli umani si fidino del processo. In COMPILOT, la correttezza non è delegata al modello. È delegata al compiler. È questa la lezione architetturale chiave.
Ma la validazione ti protegge solo se l’agente non può aggirarla. Un controllo che l’agente può modificare, saltare o contestare non è un vincolo, è un suggerimento. Quindi questi layer non possono vivere dentro il prompt dell’agente o nel suo stesso ragionamento. Devono essere confini di enforcement di proprietà della piattaforma, che l’agente si limita a invocare: il consent gate nella CDP, le regole di frequency e di collisione nella CEP, i controlli su claim e diritti nel content layer, l’audit trail nella data platform. Proporre e far rispettare i vincoli devono essere due cose separate, così che un agente veloce incontri sempre un layer più lento che non controlla. È quella separazione, non l’intelligenza del modello, a rendere il no affidabile.
Se a un agente è permesso generare audience, la CDP o il data warehouse devono poter validare identità, consenso, join, esclusioni e logiche di soppressione. Se a un agente è permesso costruire journey, la CEP deve poter validare regole di canale, frequency cap, dipendenze, criteri di uscita, holdout, esperimenti e collisioni con i programmi esistenti. Se a un agente è permesso generare contenuti, il content layer deve poter validare brand, claim, linguaggio regolamentato, localizzazione, approvazioni e diritti. E se a un agente è permesso attivare i clienti, l’organizzazione deve poter validare gli outcome, non solo gli output.
È qui che credo molte roadmap agentiche si romperanno. Aggiungeranno il layer che propone prima di aver costruito il layer che dice no. Scambieranno suggerimenti fluenti per esecuzione governata. Metteranno un agente sopra dati di cui non si fidano, journey che non possono auditare e regole di contenuto che esistono solo nella testa delle persone. Poi si stupiranno quando l’agente si comporterà esattamente come l’architettura gli ha permesso di comportarsi.
L’architettura vince sempre. Soprattutto quando l’agente è veloce.
E c’è un’asimmetria che dovrebbe stare al centro di ogni design review agentica: la reversibilità. In COMPILOT un’azione sbagliata non costa nulla. Lo schedule cattivo viene scartato, il loop riprova, e nessuno viene danneggiato dal tentativo. Il marketing non funziona così. L’email è già stata inviata. Il cliente è già infastidito. Lo sconto ha già insegnato alle persone ad aspettare. Quando il costo di un’azione sbagliata è basso e recuperabile, puoi lasciare che un agente imperfetto esplori liberamente. Quando è alto e irreversibile, il loop deve rallentare, chiedere il permesso e tenere un umano al suo interno. La reversibilità dell’azione dovrebbe stabilire l’autonomia dell’agente. Quella singola regola eviterebbe gran parte dei danni che mi aspetto di vedere.
Perché l’analogia dovrebbe renderci più prudenti, non più mistici
Non credo che la conclusione utile sia che gli agenti LLM stiano diventando coscienti. Non è un’affermazione che posso fare, e non mi serve. La conclusione utile è che lo stesso loop continua a comparire perché risolve un problema reale. Un modello statico è fragile in un ambiente dinamico. Un modello con strumenti è più utile. Un modello con strumenti e feedback è più adattivo. Un modello con strumenti, feedback, memoria e vincoli diventa operativo. Quella progressione è la storia dell’AI agentiva.
È anche il motivo per cui l’analogia umana sembra inevitabile. Riconosciamo la forma perché viviamo dentro una sua versione. Agiamo prima di sapere tutto. Impariamo attraverso le conseguenze. Ricordiamo i fallimenti in modo irregolare. Generalizziamo da troppo pochi esempi. Facciamo overfitting sul feedback recente. Ci fermiamo troppo presto quando compare una risposta abbastanza buona. Abbiamo bisogno di sistemi esterni, altre persone, strumenti, regole e istituzioni che ci impediscano di trasformare ogni pensiero plausibile in azione.
Quest’ultimo punto conta. La cognizione umana non è affidabile perché il cervello è perfetto. È abbastanza affidabile, quando lo è, perché è inserita in un’impalcatura: linguaggio, taccuini, dashboard, peer review, regolamentazione, rituali, checklist, istituzioni, scadenze, contratti e altre persone che dicono no. I buoni sistemi agentici avranno bisogno dello stesso tipo di impalcatura. Non lo stesso macchinario biologico, ma la stessa umiltà architetturale.
La domanda che farei in ogni valutazione di una piattaforma agentica
Più gli agenti entrano nel MarTech, meno utile diventa chiedere solo cosa l’agente sa fare. Una domanda migliore è: da cosa impara l’agente, e chi decide se quella lezione è corretta?
Per un benchmark di compiler la risposta è relativamente pulita: controlli di legalità e runtime misurato. Per il marketing non lo è. Una campagna che ottiene più click può essere peggiore per la fiducia del cliente. Un journey che genera più conversioni può aumentare il tasso di reclami. Un agente di scontistica può migliorare il fatturato di breve termine mentre addestra i clienti ad aspettare. Un agente di churn può prendere di mira clienti vulnerabili in modi commercialmente efficaci ed eticamente indifendibili. Un agente di contenuti può produrre testi abbastanza accurati da superare una revisione superficiale e abbastanza sbagliati da creare rischio di compliance. Il segnale di feedback non è mai neutro.
È per questo che il layer agentico non può essere valutato separatamente dall’architettura di misurazione. Qual è la ricompensa? Qual è la penalità? Cosa è escluso dall’ottimizzazione? Quali outcome richiedono revisione umana? Quali azioni sono reversibili? Quali azioni sono vietate? Di quali segnali ci si fida, e quali sono solo proxy? Chi è il proprietario della risposta?
È qui che la scomoda somiglianza umana diventa praticamente importante. Anche noi ottimizziamo a fronte di segnali incompleti. Anche noi scambiamo le proxy per la verità. Anche noi impariamo la lezione sbagliata quando l’ambiente premia il comportamento sbagliato. La differenza è che gli agenti possono farlo più velocemente, in modo più coerente e su scala più ampia. Non è un motivo per evitarli. È un motivo per progettarli come si deve.
Chiusura
Il paper COMPILOT parla di compiler. Io lo leggo come un paper sul futuro dei sistemi agentici, non perché ogni dominio sia ottimizzazione di loop, ma perché il pattern è trasferibile: un agente generativo dentro un ambiente vincolato, che agisce attraverso un repertorio limitato, impara dal feedback, porta avanti la memoria e migliora senza cambiare i propri pesi.
Quel pattern comparirà ovunque. Negli strumenti di sviluppo, nell’analytics, nel customer service, nelle marketing operations, nell’orchestrazione dei journey, nelle content supply chain, nei sistemi di decisioning che non aspettano un umano per disegnare ogni ramo. Il modello riceverà gran parte dell’attenzione. Il loop farà gran parte del lavoro, ed è il loop ciò che dobbiamo progettare, governare e auditare.
Qualche anno fa l’AI sembrava soprattutto una nuova interfaccia verso la conoscenza. Ora sta diventando una nuova interfaccia verso l’azione, ed è un cambiamento molto più grande. Una volta che un sistema può agire, il feedback smette di essere una funzione di analytics e diventa parte della cognizione. La memoria smette di essere gestione del contesto e diventa storia operativa. La governance smette di essere un documento di policy e diventa la forma del possibile.
È per questo che tutto questo sembra scomodamente umano. Non perché la macchina sia come noi in un senso completo, ma perché, quando la rendiamo utile, le diamo una piccola versione ingegnerizzata di qualcosa che riconosciamo in noi stessi: la capacità di provare, fallire, ricordare, aggiustare e riprovare.
Questo non dovrebbe renderci mistici. Dovrebbe renderci prudenti.
Fonti
Agenti LLM, loop di feedback e ottimizzazione dei compiler
- Merouani, Kara Bernou, Baghdadi - Agentic Auto-Scheduling: An Experimental Study of LLM-Guided Loop Optimization - Il paper COMPILOT che ha innescato questa riflessione. Sottoposto a peer review e pubblicato a PACT 2025, e indicizzato anche su IEEE Xplore e ACM Digital Library.
- Yao et al. - ReAct: Synergizing Reasoning and Acting in Language Models - Lavoro fondativo sull’intreccio di ragionamento, azione e feedback ambientale negli agenti basati su modelli linguistici.
- Google Research - ReAct: Synergizing Reasoning and Acting in Language Models - Sintesi accessibile del pattern ReAct e del suo loop azione-feedback.
- Shinn et al. - Reflexion: Language Agents with Verbal Reinforcement Learning - Agenti linguistici che migliorano attraverso feedback, riflessione e memoria episodica senza aggiornare i pesi del modello.
- Park et al. - Generative Agents: Interactive Simulacra of Human Behavior - Architettura di agenti basata su osservazione, memoria, riflessione e pianificazione.
- Kulveit, von Stengel, Leventov - Predictive Minds: LLMs as Atypical Active Inference Agents - Un tentativo diretto di interpretare gli LLM attraverso la lente dell’active inference. Utile, ma lo tratterei come concettuale più che come scienza consolidata.
Teoria del controllo e cibernetica
- Norbert Wiener - Cybernetics: Or Control and Communication in the Animal and the Machine (1948) - Il resoconto originale del comportamento finalizzato come loop di feedback di percezione, azione, errore e correzione.
- W. Ross Ashby - Design for a Brain: The Origin of Adaptive Behaviour (1952) - Il comportamento adattivo modellato come un sistema che cerca la stabilità attraverso il feedback, l’antenato intellettuale dei loop di questo articolo.
Riferimenti di scienze cognitive e neuroscienze
- Bubic, von Cramon, Schubotz - Prediction, Cognition and the Brain - Rassegna sulla previsione come concetto organizzatore centrale nella cognizione.
- Friston - Free-energy and the Brain - Formulazione fondativa di percezione, azione e apprendimento attraverso la minimizzazione dell’energia libera.
- Schultz - Dopamine Reward Prediction Error Coding - Rassegna sull’errore di previsione della ricompensa come meccanismo di apprendimento.
- Schacter et al. - The Future of Memory: Remembering, Imagining, and the Brain - Lavoro sulla memoria come sistema per immaginare eventi futuri e supportare la pianificazione.


