Questo articolo è una traduzione assistita dall’AI dell’originale in inglese, revisionata dall’autore.
In questo settore tutti discutono di piattaforme.
Quale CDP sia la migliore. Se le CEP abbiano ancora bisogno di un data layer separato. Se il modello composable sia finalmente abbastanza maturo. Se una suite sia più sicura del best-of-breed.
Sono domande reali, ma vengono a valle di una più importante che spesso viene saltata:
Come stai collegando tra loro la CDP e la CEP, e hai riflettuto su cosa implichi quella scelta architetturale?
Il pattern di integrazione conta più delle singole piattaforme.
Puoi comprare una CDP solida e una CEP solida e ritrovarti comunque con personalizzazioni obsolete, audience incoerenti, logica di segmentazione duplicata e problemi di governance. Non perché le piattaforme siano scadenti, ma perché l’architettura che le collega crea vincoli che nessuna feature list di vendor può rimuovere del tutto.
Dopo anni passati a progettare e implementare stack di customer engagement cross-channel, l’ho visto accadere ripetutamente. I team passano mesi a valutare le piattaforme e pochissimo tempo a valutare il modello di integrazione. Poi i problemi compaiono sei mesi dopo il lancio, quando l’architettura inizia a operare sotto pressione reale.
Questa è la Parte 1 di una serie in due parti.
Qui mappo i tre principali pattern architetturali: cosa sono, come funzionano, chi li implementa e cosa ti costa ciascuno.
Nella Parte 2 passerò dalla mappatura alla decisione: i criteri che dovrebbero guidare quale pattern abbia senso per la tua organizzazione, e i red flag da tenere d’occhio prima di impegnarti.
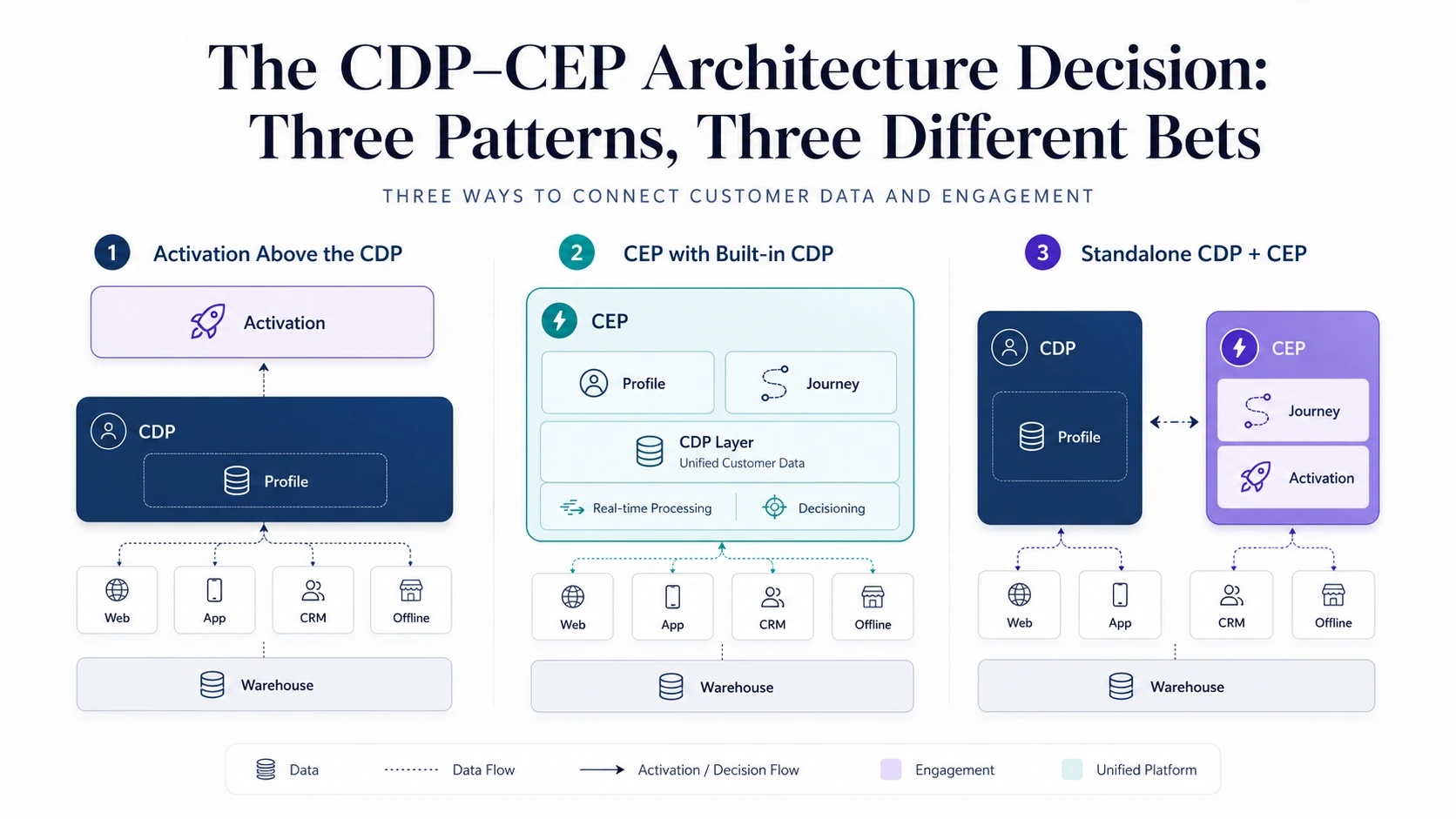
I tre pattern
Esistono molte varianti di implementazione, ma la maggior parte delle architetture CDP–CEP rientra in tre pattern.
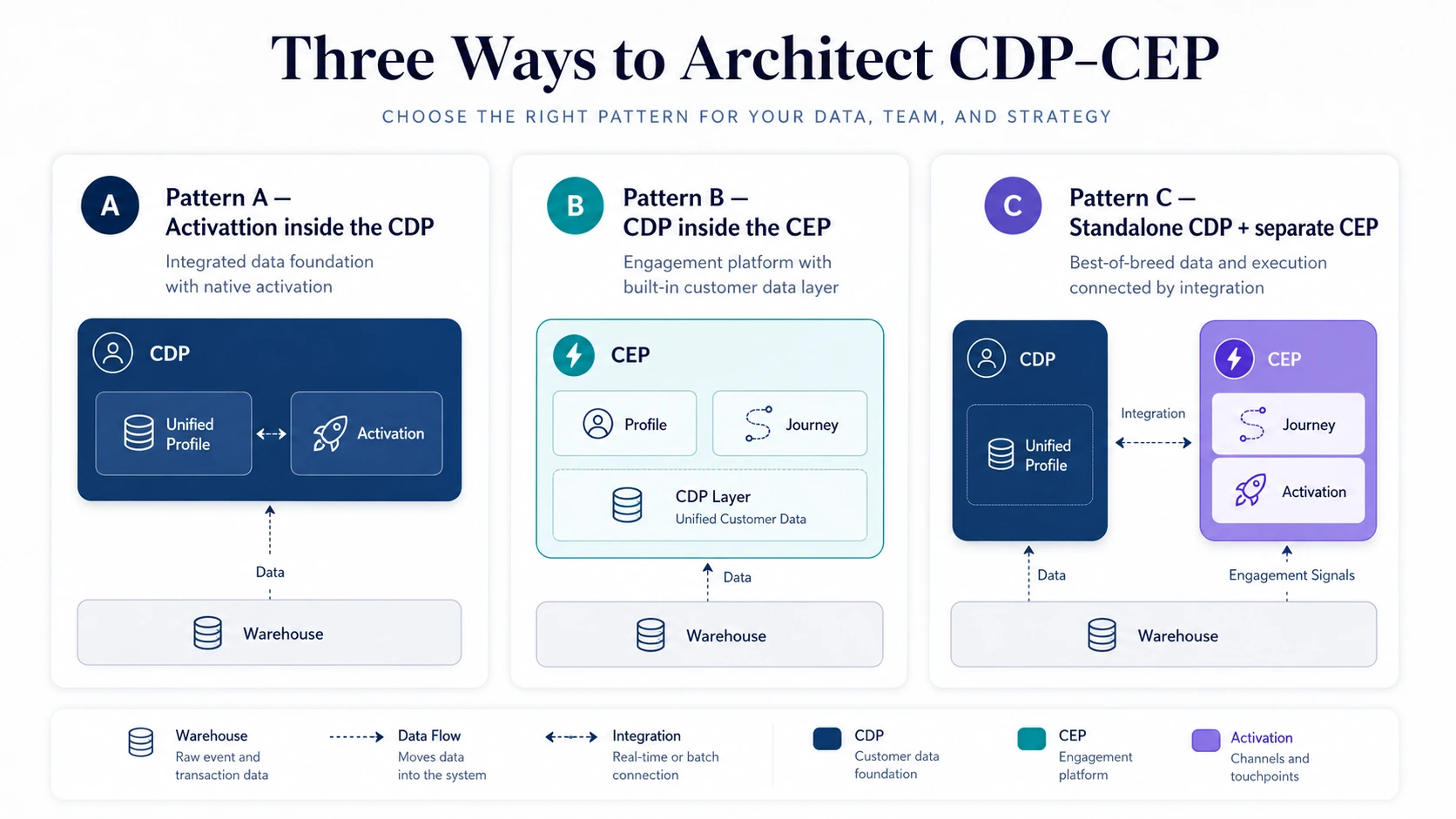
Pattern A: attivazione dentro la CDP.
Il vendor della CDP si espande verso l’alto, aggiungendo orchestrazione dei journey, esecuzione delle campagne e attivazione sui canali sopra le fondamenta dei dati. La CDP resta il system of record primario, mentre l’attivazione diventa una capability nativa della stessa piattaforma più ampia.
Pattern B: la CDP dentro la CEP.
Il vendor della CEP si espande verso il basso, costruendo identity resolution, unificazione dei profili, ingestion degli eventi e segmentazione direttamente nella piattaforma di engagement. La CEP diventa il sistema combinato sia per i dati sia per l’esecuzione.
Pattern C: CDP standalone con una CEP separata.
Best-of-breed classico. Una CDP dedicata gestisce identità, profili, consenso e audience. Una CEP dedicata si occupa di orchestrazione dei journey e consegna sui canali. Le due sono collegate tramite API, streaming, Reverse ETL, sincronizzazione su file o un layer di cloud data warehouse condiviso.
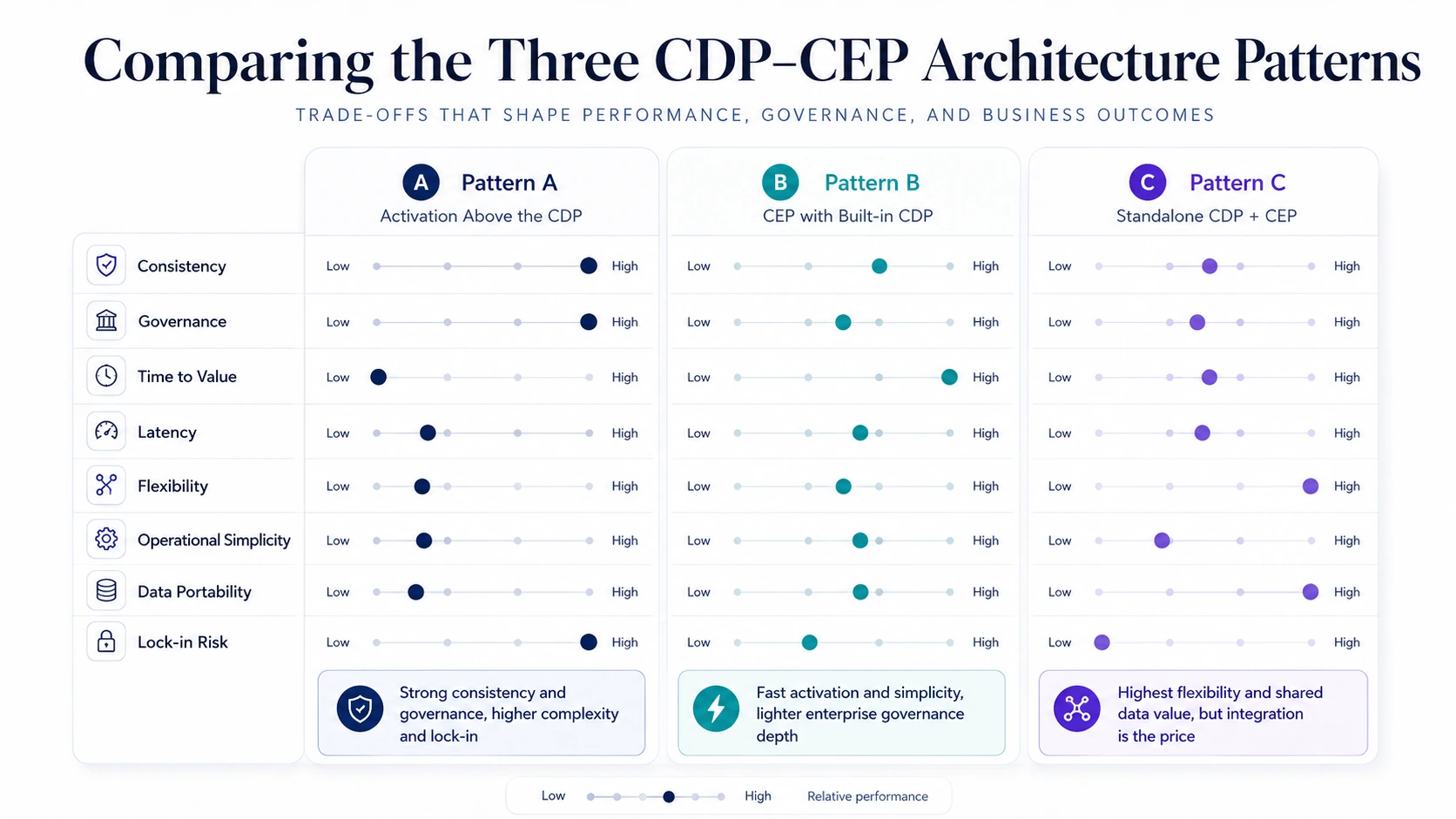
Nessuno di questi pattern è intrinsecamente giusto o sbagliato. Tutti e tre sono attivi in ambienti di produzione. Tutti e tre possono funzionare. Tutti e tre possono fallire.
La differenza non è un’astratta eleganza architetturale. La differenza sta nei trade-off che ciascun pattern crea attorno a qualità dei dati, latenza, governance, costo, complessità operativa e ownership organizzativa.
L’attuale mercato delle CDP ha più senso se letto attraverso questa lente. Ciò che sta cambiando non è se i dati dei clienti contino. È dove risieda la responsabilità del customer context: dentro una suite, dentro la piattaforma di engagement, o più vicino all’infrastruttura dati enterprise.
Pattern A: attivazione dentro la CDP
Come funziona
In questo pattern, la CDP è la fondamenta. Sopra di essa, lo stesso vendor fornisce orchestrazione dei journey, decisioning, strumenti di campagna e attivazione sui canali.
Il data layer e l’execution layer condividono lo stesso identity graph, modello di profilo e framework di governance. Non c’è un passaggio separato di sincronizzazione delle audience tra la CDP e la CEP perché, dal punto di vista architetturale, fanno parte della stessa famiglia di piattaforme.
Esempi tipici includono Adobe Real-Time CDP con Adobe Journey Optimizer su Adobe Experience Platform, Salesforce Data Cloud come fondamenta di identità e profili per Salesforce Marketing Cloud, e l’AI Marketing Cloud di Treasure Data, che estende la sua eredità da CDP verso orchestrazione e attivazione. Twilio Segment con Engage è una versione più leggera della stessa direzione. L’idea comune è semplice: mantenere customer context e attivazione del cliente dentro un unico ambiente governato.
I punti di forza reali
Il vantaggio principale è la coerenza.
Il profilo usato per l’identity resolution è lo stesso profilo usato per segmentazione, decisioning e attivazione. Non c’è una copia separata del profilo cliente spinta in un altro strumento, né un secondo sistema che cerca di reinterpretare lo stesso stato del cliente. Conta più di quanto sembri.
In un’architettura disaccoppiata, finisci spesso per mantenere due definizioni della stessa cosa: un segmento nella CDP e una corrispondente audience o entry condition nella CEP. Ogni volta che una cambia e l’altra no, l’organizzazione crea drift. Il Pattern A riduce questa classe di problemi perché la logica di attivazione sta più vicina al profilo governato. La governance è il secondo punto di forza importante. Consenso, policy di utilizzo dei dati e regole di soppressione possono essere applicate in modo più coerente quando il data layer e l’activation layer condividono lo stesso modello di governance. In piattaforme come Adobe Experience Platform o Salesforce Data Cloud, questo dipende comunque da configurazione corretta, data labelling, design delle policy e disciplina operativa. Ma l’architettura ti dà una base più solida di una catena di job di soppressione scollegati tra sistemi. Il terzo punto di forza è l’allineamento strategico con il consolidamento delle piattaforme enterprise. I grandi vendor stanno investendo molto in data e activation layer integrati. L’acquisizione di Informatica da parte di Salesforce, completata a novembre 2025, è un segnale chiaro di dove si stia muovendo il capitale enterprise: integrazione più profonda tra infrastruttura dati, customer context e attivazione. Anche l’Industry Update di febbraio 2026 del CDP Institute indica una concentrazione continua nei grandi vendor integrati, con un piccolo gruppo che rappresenta una quota dominante dell’occupazione e dei finanziamenti nella categoria CDP. Infine, AI e decisioning beneficiano di un profilo governato più completo. Score predittivi, modelli di propensity e logica di next-best-action valgono di più quando possono operare sullo stesso customer context che usa l’attivazione. Il Pattern A rende questo più facile rispetto ad architetture in cui i modelli operano su un profilo mentre le campagne vengono eseguite contro un’altra proiezione di quel profilo.
I costi reali
Il primo costo è l’usabilità.
Le piattaforme guidate dalla CDP sono spesso progettate prima dalla prospettiva dell’architettura dei dati e della governance. Le capability di attivazione come journey builder, workflow di campagna, sperimentazione e content operation vengono aggiunte sopra. Sono migliorate parecchio, ma non sempre risultano naturali per i marketer nel lavoro quotidiano quanto le piattaforme nate specificamente per l’esecuzione dell’engagement. Adobe Journey Optimizer è diventato più capace, ma resta un ambiente complesso. Salesforce Marketing Cloud è potente, ma porta con sé layer architetturali legacy che richiedono competenza e disciplina per essere gestiti bene. Nel Pattern A, l’organizzazione spesso guadagna coerenza dei dati ma accetta un carico operativo più alto per marketer e team di piattaforma. Il secondo costo è commerciale.
Il pricing delle CDP segue spesso una logica da infrastruttura dati: profili, righe, eventi, chiamate API, volume di dati. Quel modello ha senso quando la CDP è principalmente un data layer. Può diventare più difficile quando lo stesso ambiente viene usato anche per attivazione ad alto volume. Prima di scegliere il Pattern A, il modello commerciale va messo sotto stress contro il volume reale delle campagne, non solo contro il conteggio dei profili. Il terzo costo è il lock-in.
Il tuo identity graph, le definizioni delle audience, la logica del consenso, l’orchestrazione dei journey, le regole di decisioning e lo storico dei canali vivono sempre più dentro l’ecosistema di un singolo vendor. Questo può essere coerente. Può anche diventare difficile da districare. Migrare via dal Pattern A non è solo sostituire uno strumento. Significa ripensare il sistema nervoso centrale dello stack di marketing.
A chi si adatta
Il Pattern A si adatta a organizzazioni già impegnate in un grande ecosistema enterprise come Adobe Experience Cloud o Salesforce Customer 360.
Si adatta anche ad aziende dove governance e compliance sono non negoziabili, e dove l’utilizzo dei dati dei clienti deve essere applicato a livello di infrastruttura piuttosto che solo attraverso i processi.
È più adatto a organizzazioni con la maturità tecnica per gestire piattaforme complesse, e con sufficiente allineamento organizzativo tra marketing, dati e IT da far funzionare un modello di piattaforma condivisa.
Il Pattern A non è la via più facile. Ma quando l’organizzazione è pronta, può fornire la connessione più pulita tra dati dei clienti governati e attivazione.
Pattern B: la CDP dentro la CEP
Come funziona
In questo pattern, la piattaforma di engagement assorbe molte capability da CDP.
La CEP fa ingestion degli eventi, memorizza attributi utente, costruisce profili, risolve le identità per scopi di marketing, crea segmenti e attiva journey dallo stesso ambiente. Invece di una CDP che alimenta la CEP, è la CEP a diventare il sistema di dati ed esecuzione per il marketing.
Bloomreach Engagement si è posizionata esplicitamente in questa direzione, usando l’idea di una Customer Data and Engagement Platform. Insider One segue una logica simile, combinando raccolta dati, segmentazione, personalizzazione e orchestrazione dentro un’unica piattaforma. Braze è più sfumata. Ha una solida ingestion di eventi comportamentali, attributi utente, segmentazione e attivazione in tempo reale, ma generalmente non si posiziona come una CDP enterprise completa. La sua risposta alla domanda sull’architettura dei dati include sempre più connessioni dirette ai cloud data warehouse, incluso Snowflake Data Sharing, piuttosto che cercare di sostituire ogni data layer a monte. L’idea comune nel Pattern B è la semplicità operativa: il marketing può lavorare in un unico ambiente dove dati e attivazione sono strettamente connessi.
I punti di forza reali
Il time to value è il vantaggio più chiaro.
Non c’è un procurement separato per la CDP, nessun grande progetto di integrazione, e nessun data layer aggiuntivo da implementare prima che il marketing possa iniziare ad attivare. Il team collega le sorgenti dati, configura profili ed eventi, costruisce segmenti e lancia campagne dalla stessa piattaforma. Per molte organizzazioni, non è un beneficio minore. È la differenza tra lanciare in settimane e lanciare in trimestri.
La latenza è un altro vantaggio reale. Quando ingestion, segmentazione e attivazione dei journey avvengono nello stesso sistema, il percorso dall’evento all’azione può essere molto breve. Per use case come l’abbandono del carrello, la personalizzazione in-session, i trigger comportamentali o il mobile engagement, il Pattern B può essere estremamente efficace perché non c’è un passaggio di sincronizzazione esterno tra aggiornamento del profilo e attivazione. Anche la semplicità operativa conta. Un solo vendor. Un’unica interfaccia. Un solo posto dove fare debug. Un unico modello operativo per il team di marketing. Per organizzazioni senza un solido supporto di data engineering, può essere un vantaggio decisivo. Questo è uno dei motivi per cui le CDP orientate alla delivery e le piattaforme di engagement con capability di dati integrate hanno guadagnato rilevanza. L’investimento da 300 milioni di dollari di Rokt e la fusione con mParticle, annunciati a gennaio 2025, riflettevano una logica di mercato simile: combinare una CDP real-time con il decisioning per l’ecommerce per sbloccare esperienze più rilevanti al momento della transazione.
I costi reali
La limitazione centrale è la profondità della governance.
Le capability da CDP dentro una CEP sono di solito ottimizzate per l’attivazione di marketing, non per la gestione dei dati enterprise. Sono molto brave a rispondere a domande come: chi dovrebbe ricevere questo messaggio, chi ha compiuto questo evento, chi appartiene a questo journey, e chi dovrebbe essere soppresso da questo canale? Sono meno adatte a domande enterprise come: quali sistemi hanno consumato questo attributo del cliente, su quale base giuridica, da quale sorgente, e con quale policy di retention? Questa distinzione conta.
L’identity resolution di livello marketing non è la stessa cosa del master data management di livello enterprise. Far corrispondere gli utenti per email, device ID o customer ID può bastare per l’attivazione. Può non bastare per un’identità cliente cross-dipartimentale tra service, commerce, analytics, rischio e finance. La seconda limitazione è la portabilità dei dati.
Quando il profilo unificato vive dentro la CEP, gli altri sistemi non lo consumano in modo naturale. Piattaforme di analytics, strumenti di data science, destinazioni di paid media, applicazioni di customer service o reporting enterprise possono aver bisogno tutti di accedere al customer context. Esportare i profili fuori dalla CEP reintroduce la complessità di integrazione che il Pattern B inizialmente ti aveva aiutato a evitare. La terza limitazione è la profondità disomogenea tra i vendor.
Alcune CEP hanno investito molto in capability da CDP integrate. Altre offrono arricchimento dei profili e segmentazione che non vanno confusi con una customer data platform completa. Prima di dare per scontato che una CEP possa sostituire una CDP, l’organizzazione dovrebbe testare le domande difficili: stitching da anonimo a noto, identificatori multipli, profili duplicati, ereditarietà del consenso, comportamento cross-device, eventi storici, attributi calcolati, governance dello schema ed esportabilità dei profili.
A chi si adatta
Il Pattern B si adatta a organizzazioni dove il marketing è l’owner primario dell’attivazione del cliente e dove la condivisione dei dati cross-dipartimentale non è ancora un requisito importante.
È particolarmente forte per brand e-commerce, retail e direct-to-consumer con un modello di dati relativamente lineare e una forte necessità di attivazione rapida sui canali di proprietà come email, push, SMS, in-app, web e WhatsApp. Si adatta anche a team che devono muoversi in fretta e non hanno la capacità di data engineering per progettare, costruire e mantenere un layer di integrazione CDP–CEP separato.
Il Pattern B è spesso la scelta più pragmatica. Ma va scelto con una chiara consapevolezza del suo limite: risolve l’attivazione di marketing più velocemente di quanto risolva la governance enterprise dei dati dei clienti.
Pattern C: CDP standalone con una CEP separata
Come funziona
In questo pattern, la CDP e la CEP restano piattaforme indipendenti collegate da un layer di integrazione.
La CDP gestisce identity resolution, archiviazione dei profili, logica del consenso, modellazione delle audience e governance dei dati dei clienti. La CEP consuma audience, attributi, eventi o segnali calcolati dalla CDP per orchestrare i journey e consegnare i messaggi. La connessione può assumere diverse forme: eventi in streaming, API, webhook, Kafka, Reverse ETL, sincronizzazione su file, polling delle API o lettura diretta da un cloud data warehouse condiviso. Nelle architetture composable, il cloud data warehouse diventa la fondamenta. Snowflake, BigQuery o Databricks contiene i dati dei clienti governati. Una CDP composable o un layer di Reverse ETL modella le audience e le sincronizza verso le piattaforme di engagement a valle. Esempi comuni includono Tealium o mParticle che alimentano Braze o Salesforce Marketing Cloud; Segment o Amperity che fungono da customer data layer per più strumenti di esecuzione; oppure Hightouch, Census e strumenti warehouse-native simili che sincronizzano i dati dei clienti dal warehouse verso le CEP e le destinazioni media. L’idea comune è la separation of concerns: il customer data layer serve più di una piattaforma di attivazione.
I punti di forza reali
La flessibilità è il vantaggio distintivo.
Puoi sostituire ciascun layer in modo indipendente. Se l’organizzazione sceglie una CEP migliore tra due anni, la CDP e il modello di identità possono restare. Se la strategia dei dati cambia per via di una fusione, di una nuova architettura di warehouse o di un programma di governance, la CEP non deve necessariamente essere sostituita. Il Pattern C rende inoltre la CDP un layer di servizio condiviso.
Nel Pattern A e nel Pattern B, i profili cliente servono spesso principalmente un solo ambiente di esecuzione. Nel Pattern C, la CDP può alimentare piattaforme di engagement, analytics, paid media, strumenti di sperimentazione, customer service, direct mail, sistemi di call center e use case di data science. Quella superficie di ritorno più ampia è il vero motivo per cui il Pattern C esiste.
Anche la portabilità dei dati è più forte. Nella variante composable, i dati restano nell’infrastruttura governata che l’organizzazione già controlla. Gli strumenti di attivazione consumano gli attributi, i segmenti o i segnali necessari, ma le fondamenta dei dati dei clienti non si spostano in un silo di vendor. Ecco perché i modelli di CDP warehouse-native e composable hanno guadagnato slancio. Per le organizzazioni con piattaforme di cloud data mature, è sempre più naturale tenere i dati dei clienti vicino al warehouse e usare gli strumenti di attivazione come consumatori di quei dati, piuttosto che fare di ogni strumento un’altra parziale source of truth.
I costi reali
La complessità di integrazione è il costo inevitabile.
Due piattaforme significano due modelli di dati, due insiemi di identificatori, due team operativi, due contratti, due superfici di monitoraggio e un confine critico tra dati e attivazione.
Quel confine è dove il Pattern C riesce o fallisce.
L’audience costruita nella CDP non è automaticamente l’audience usata nella CEP. A meno che l’integrazione non sia progettata, monitorata e governata con cura, compare il drift. La CDP dice che un cliente appartiene a un segmento. La CEP non è d’accordo perché la sua copia locale è in ritardo, incompleta o trasformata in modo diverso. La latenza è il secondo costo strutturale.
Per la maggior parte degli use case di lifecycle, non conta. Campagne giornaliere, sequenze post-acquisto, journey di riattivazione, comunicazioni di loyalty e i normali flussi di carrello abbandonato possono tollerare minuti o ore di latenza senza un impatto visibile per il cliente. Per use case realmente real-time, il layer di integrazione diventa più esigente. Trigger sotto il minuto, interventi sulla sessione live e logica di soppressione immediata richiedono event streaming, una gestione attenta dello stato e una solida osservabilità. Il Pattern C può supportarlo, ma non lo ottiene gratis. Il terzo costo è l’ownership operativa.
Quando un trigger non scatta, il percorso di debugging attraversa più sistemi. L’evento è stato catturato? L’identità è stata risolta? L’audience si è aggiornata? La sincronizzazione è stata eseguita? La CEP ha fatto ingestion dell’aggiornamento? Il journey ha valutato il cliente correttamente?
In uno stack mal strumentato, quella domanda può divorare giorni.
A chi si adatta
Il Pattern C si adatta ad aziende con reali requisiti cross-dipartimentali sui dati dei clienti.
È il pattern naturale quando la CDP serve marketing, service, commerce, analytics, paid media e data science, non solo la piattaforma di engagement.
Si adatta anche a organizzazioni con un cloud data warehouse maturo e un team di data engineering capace di farsi carico del layer di integrazione come infrastruttura core.
Il Pattern C non è l’architettura più semplice. Di solito non è la più veloce. Ma quando il customer data layer deve servire l’intera azienda, è spesso la più difendibile.
Di cosa non parla davvero questa scelta
Questa decisione architetturale non è in primo luogo una questione di valutazione delle piattaforme.
Non puoi rispondere a “quale pattern è giusto per noi?” leggendo i Magic Quadrant, confrontando le demo dei vendor o assegnando punteggi a checklist di funzionalità.
Quelle cose contano, ma solo dopo che il fit architetturale è chiaro. Le vere domande sono organizzative:
- Chi è l’owner del customer data layer?
- Quanto è matura l’infrastruttura dati?
- Quanta governance è richiesta?
- Quante superfici di attivazione devono consumare il profilo cliente?
- Quanto è reale il requisito di real-time?
- Chi gestirà il confine di integrazione quando qualcosa si rompe?
I Pattern A, B e C possono funzionare tutti. La differenza non è quale sia il migliore in generale. La differenza è quale corrisponda alla reale capacità dell’organizzazione di operare, governare ed evolvere l’architettura. È da qui che inizia la Parte 2.
Fonti
CDP Institute / Customer Data Alliance
- CDP Industry Update: February 2026
- Customer Data Alliance and CDP Institute release new CDP Industry Update
CDP.com
- Do You Need a CDP with an Engagement Platform?
- Packaged vs Composable CDP: An Outdated Framing
- CDP Industry Statistics 2026: Market Size & Trends
Customer.io
Blueshift
MarTech.org
Dinmo
Salesforce
Rokt / mParticle